网络安全产品营销人员可能会这么向你推荐:有个新式的先进网络入侵设备,运用当前超智能的机器学习 (ML) 根除已知和未知入侵。这个 IDS 设备真是太聪明了,可以学习你网络上的正常和不正常事件,只要一发现异常就会马上通知你。或者说,这是一款可以封锁所有恶意流量的入侵预防系统 (IPS)。这款 AI 驱动的解决方案能达到 99% 的攻击检测准确率。而且,连此前未知的攻击都可以检测哦!听起来真是好诱人,对吧?

但,销售说得天花乱坠,真相令人欲哭无泪。真正了解自治安全 (autonomous security) 和机器学习的人不会被市场营销人员忽悠。主要原因有两个:
1. 上述推销混淆了攻击检测与入侵检测。攻击未必成功;入侵则肯定是成功的。假设你检测到 5 个新攻击,但只有 1 个是真实的入侵。难道你不想只专注于那个成功的入侵,而无视那 4 个失败的攻击吗?
2. 采用 ML 的安全未必足够健壮,可能在某个数据集上(很多情况下都是供应商的数据集)效果良好,而在另一个数据集上(你自己的真实网络)表现糟糕。总之,攻击者的任务是规避检测,而 ML 研究已证明做到这一点并不难。
简单讲,ML 算法通常无意打败现实中随时准备攻击的对手。事实上,对抗性机器学习在学术研究领域都还只处在起步阶段,更不要说运用 ML 技术的实际产品了。别误会,有些 ML 研究和研究人员很棒,但若说已达到可驱动完全自治的程度,那就是在说笑了。
自治安全的愿景是由机器检测、响应和防护。而上面列出的两个原因,让 ML 于完全自治无益。总结一下就是:
- 忙于追逐攻击(大部分攻击都是不成功的)的完全自治系统毫无用处;预防真正的入侵才是重点。
- 不健壮的系统很容易被绕过。从部署的那一刻起,攻击者就会不断试错,找出可行方法,最终仍成功入侵。
- 但我们不妨再深入探索一下网络安全与 ML,尤其是在入侵检测与预防语境下。
检测率 != 真实入侵
对 ML 产品不买账的一个关键因素是:这些东西常把检测率(经常列为准确率)跟真正攻击率混为一谈。在 IDS 语境中,用户想要识别真正的入侵。他们不想研究攻击者是谁。他们想要在攻击者确实成功的时候检测出来。但不幸的是,这些愿望仅仅是愿望,不是现实。
不知道读者有没有注意到,文章开篇其实用了偷梁换柱的诱饵推销手法。
先以谈论入侵检测勾起兴趣,但后面却只给出了攻击检测准确率。放出一个诱饵,然后偷换概念掉包。看出来没有?
检测入侵和检测攻击是不一样的。攻击是入侵的潜在指征,但攻击可能成功,也可能不成功。入侵则是有人切切实实成功了。
以端口扫描(比如说用 nmap)和针对性漏洞利用为例。脚本小子用 nmap 执行端口扫描,对目标系统尝试默认密码,基本突破不了系统防线,但针对性攻击就完全不一样了。针对性攻击成功突破系统安全防线的可能性很高。用户都想要好钢用在刀刃上,将有限的资源、人力和精力花在真正的入侵上。
需要理解的一个关键概念就是基本发生率谬误。这也不太算得上谬误,只是人类在即时理解统计数据上的困难。(有数学头脑的读者可以看看卡耐基梅隆大学 Stefan Axelsson 的论文。想惹恼销售代表的话,问问他有没有读过这篇论文。)这种认知上的谬误很常见,比如赌徒觉得自己手气正旺的时候。他们不时赢上一把,然后就觉得自己是“赢家”了。同样的原则可以应用到安全上——如果你的 ML 算法不时命中,你的大脑会让你误以为这算法真的有效。
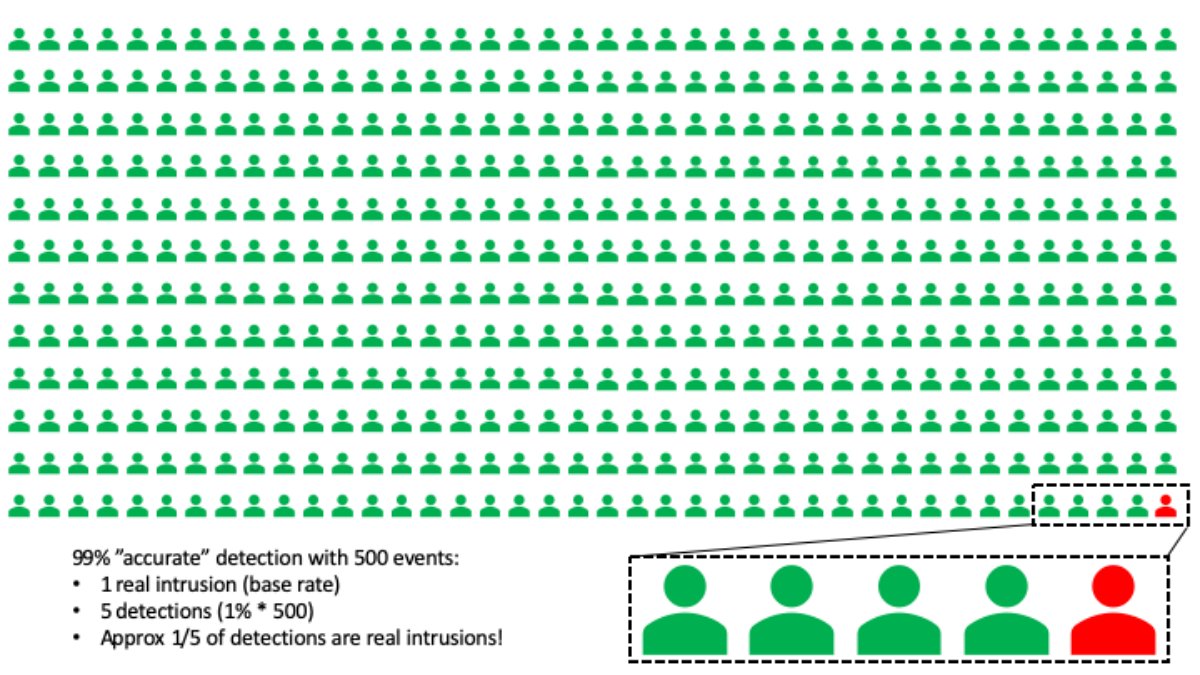
典型的基本发生率谬误场景是这样的:去体检,做了项准确率 99% 的某病筛查。坏消息:检查结果显示你已罹患该疾病。好消息:该疾病本身相当罕见。事实上,500 个人中才会出现一例。那你真的患上该疾病的概率到底是多少呢?
谬误就出现在这里:大多数人凭直觉会认为,既然检查的准确率是 99%,那我就极有可能患上那病了。然而,数学对此表示反对。实际上,你罹患该疾病的概率仅 20% 左右。怎么会这样?
可以这么想:99% 准确率的检查意味着 100 个人里面有 1 个的检查结果为阳性。但是我们知道,500 个人里才会出现一例病患。500 次检查,检测出 5 个人,但其中仅 1 例是真阳性,也就是真阳性概率仅约 20%。(如果你是数学家的话,可以用贝叶斯定理计算下精确的概率。此处用近似值是因为近似值比条件概率更好对付些。)
数字越大,谬误越严重。比如说,假设真正的入侵率仅百万分之一。99% 检测准确率情况下,每个真正的警报伴随有约 9,999 次误报。谁有那么多时间去追逐这么多误报?
这种谬误应用到 IDS 和任何算法上,无论是不是机器学习吧,会怎么样?如果实际成功入侵率很低,那即便 99% 准确的 IDS (如销售所言)也会产生大量误报。安全运营中心 (SOC) 的一条经验法则就是,一位分析师一小时能处理 10 起事件。如果几乎每起事件都只是攻击(误报)而不是真实入侵,那最好情况就是分析师被误报淹没,最坏情况就是分析师渐渐学会了无视 IDS。
实际上,数学分析显示,几乎什么误报率都太高了。
机器学习不健壮
此处的健壮性指的是:攻击者已预期到的情况下仍然有效吗?从攻击者的角度做个类比。假设,你想靠走私发家。战战兢兢通过安全检查站的时候,哔哔哔哔,被逮了。那目前为止一切安好;司法部门(类比中的 IDS)成效显著。之所以有成效,是因为你根本不知道他们到底要查什么,可能触发了某些东西。
作为有志入行的罪犯,接下来你会怎么做呢?最自然的事情就是摸清检查站的部署和检查规则,然后规避检查,对吧?换句话说,一旦你摸清防御,你就会找到绕过防御的方法。攻击者同理。
只有在攻击者改变攻击方法时仍能检测的 IDS 系统,才能算作是健壮的 IDS 系统。关键问题就在于:目前,ML 看起来有吸引力是因为攻击者还没开始尝试骗过它。而一旦你已经部署了靠 ML 检测的系统,攻击者就将注意到自己无法突破,进而尝试绕过之。
此处适用一套所谓的“没有免费午餐理论” (NFL)。(原始论文和易读摘要版链接均附在文末,可能需要点数学头脑才能理解。)该 “没有免费午餐” 理论讲的是,不存在对每个问题都应用良好的通用模型。安全语境下,其含义就是,对任意 ML 算法,对手都可以创建一个违反假设的变种出来,让 ML 算法表现十分糟糕。
当前安全领域 ML 研究难以证明 ML 算法的健壮性。例如:
1. Carrie Gates 和 Carol Taylor 在很多方面质疑基于 ML 的 IDS,其中健壮性(还有训练数据质量)就是一个主要的不足之处。
2. 恶意软件编写者经常利用 VirusTotal (运行着很多商业反恶意软件解决方案的系统)修改他们的恶意软件以规避检测。
3. 2016 年,弗吉尼亚大学的研究人员证明自己可以绕过检测 PDF 恶意软件的最先进机器学习算法。可以在 https://evademl.org/ 查看其结果。重点是:研究中用到的所有样本,他们都能自动找出可绕过 ML 分类器的变种。进一步研究显示,两个简单的改变,就有 47% 的概率骗过 GMail 的恶意软件分类器。谷歌不孤单,其他基于 ML 的杀软引擎也一样容易被骗。
4. 目前,Lujo Bauer 带领的卡耐基梅隆大学研究团队已证明,可以 3D 打印出一副眼镜,诱使最先进的人脸识别算法将识别目标认为是另一个(特定的)人。最简单的例子:攻击者完全可以用 3D 打印的眼镜混过机场人脸识别安检。虽然领域可能看起来略有差异,但道理是相通的——ML 在规避技术面前不堪一击。
5. 在入侵检测领域,著名人物 Vern Paxon(Bro 网络 IDS 架构师)和 Robin Summers 发表了一篇很棒的综述,讲述入侵预防中 ML 和异常检测所面临的挑战。
经验教训就是:攻击者会学习你的防御,只要防御不够健壮,他们总能绕过。
为什么对ML不买账
基本上,以 ML 为卖点的自治安全营销,在真专家面前都讨不了好。如前文所述,原因有两个。
1. AI 和机器学习 IDS 产品常不自知自己有多容易被绕过。即使刚部署时检测效果惊人,那也只是昙花一现。
2. 坚实的数学分析显示,几乎任何误报率——即使看起来低到不能更低的那种,在真实入侵相对(与攻击相比)罕见的情况下都太高了。
而且,这还仅仅是个开始。还有其他技术问题本文没有触及,比如用来训练的数据是否适用于你的网络。谷歌和 AT&T 这样的大公司算是有海量数据了,但在这方面依然问题不断。另外,组织问题也无法回避,比如公司服务水平协议 (SLA) 是否经过调整,以便员工不用不用处理未知或奇点事件。成熟的安全运营中心一般会先摸清自身事件处理能力,然后适当调低检测器报告阈值。
建议
首先,想清楚自己是只想要个短期解决方案,还是想要具有防规避健壮性的长期解决方案。如果只想滤掉互联网浮渣,新型机器学习产品可能有所帮助。然而,并没有科学共识表明这些产品扛得住攻击者的试探和了解。
其次,认真思考自己到底想检测什么:是想研究攻击者,还是负责响应真正的问题?比如说,基本发生率谬误已经告诉我们,如果公司每次的攻击入侵率相对较低(如果确实不知道的话可以去问公司安全团队),数学分析已揭示残酷现实:任何方法——无论是否基于 ML,都对你没用。
那么 ML 真正有用的地方在哪儿呢?此事尚无定论,但一般而言,ML 是基于统计的,更适合想相对提升统计准确率的场景。此处用“统计”这个词是有所指的:你得接受存在风险的事实。例如,谷歌就在利用机器学习提升广告点击率上大获成功,因为 5% 的提升都意味着百万级(十亿级?)的收益增长。但,对要为公司安全负责的你而言,5% 就够了吗?
ML 有所帮助的另一个方面是滤掉低级攻击者。例如采用著名漏洞利用程序的脚本小子。这种情形下我们已经不需要健壮了,因为就没想着对付真想骗过 ML 算法的人。
最后重申一点:正在研究 ML 的研究人员和研究项目很棒。我们需要更多更好的 ML。我们仅仅是还没研究到普通用户期待的那种程度而已。
应用安全(至少部分应用安全)完全自治是有可能的。原因在于:
1. 应用安全测试技术,比如模糊测试,是零误报的。
2. 攻击者控制不了你部署什么应用,也就谈不上绕过。
至于说 ML 加持的 IDS 有没有可能成为完全自治的网络防御,至少现在不行。
Stefan Axelsson 的论文:
http://people.scs.carleton.ca/~soma/id-2007w/readings/axelsson-base-rate.pdf
没有免费午餐理论:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.390.9412&rep=rep1&type=pdf
NFL 易读版:
Robin Summers 的 ML 面临挑战综述:
https://personal.utdallas.edu/~muratk/courses/dmsec_files/oakland10-ml.pdf)
相关阅读


