Beaver 是由日志易自主研发、安全可控的搜索引擎,由 Master、Broker 和 Datanode 三部分组成,已广泛应用于存储和分析大型分布式系统生成的日志。Beaver 拥有大量与性能相关的配置项,由于手动配置费时费力,并且有时需要修改相关配置以适配特定环境,所以自动调整配置参数优化性能是当前迫切需要解决的问题。
一、背景调研
目前业界有许多自动调参的项目和算法实现,例如 CMU 开源的关系型数据库自动调参工具 OtterTune[1]、PingCAP 仿作的 TiKV 自动调参工具[2]等,都为我们提供了大量的论文以及开源算法代码。
1、 OtterTune
数据库有很多参数,比如 MySQL 有几百个参数,Oracle 有上千个参数。这些参数控制着数据库的方方面面,很大程度上影响了如缓存容量和检查点频次等数据库性能。
对于不同的硬件配置,不同的工作负载,对应的最优参数文件都是不同的,这些复杂性令数据库调优变得更加困难。DBA(Database Administrator,即数据库管理员)不能简单地重复使用之前调好的参数文件,他们需要花大量时间根据经验来调优数据库的参数,而公司则需要花大价钱来雇佣资深 DBA。
为解决上述问题,卡内基梅隆大学数据库小组的教授、学生和研究人员开发了一个数据库自动调参工具 OtterTune,它能利用机器学习对数据库的参数文件进行自动化调优,利用已有的数据训练机器学习模型,进而实现自动化地推荐最优参数。它能很好地帮助 DBA 进行数据库调优,将 DBA 从复杂繁琐的调参工作中解放出来。
OtterTune 的目的是为了帮助 DBA,让数据库部署和调优更加容易,用机器学习代替人工来完成数据库调参这个冗繁但又很重要的工作,让技术人员甚至不需要专业知识也能顺利完成。
OtterTune 分为客户端和服务端,目标数据库是用户需要调优参数的数据库:
- 客户端安装在目标数据库所在的机器上,收集目标数据库的统计信息,并上传到服务端。
- 服务端一般配置在云上,获取到客户端的数据之后,开始训练机器学习模型并推荐配置文件。
客户端接收到推荐的配置文件后,配置到目标数据库上,并测量其性能。以上步骤可重复进行,直到用户对其推荐的配置文件满意为止。
2、AutoTiKV
AutoTikv 是一个用于对 TiKV 数据库进行自动调优的工具。它是根据 SIGMOD 2017年发表的一篇论文所设计[3],能够使用机器学习模型对数据库参数进行自动调优。
AutoTiKV 吸取了 OtterTune 的设计理念,并简化了相关结构。
设计的调优过程如下:
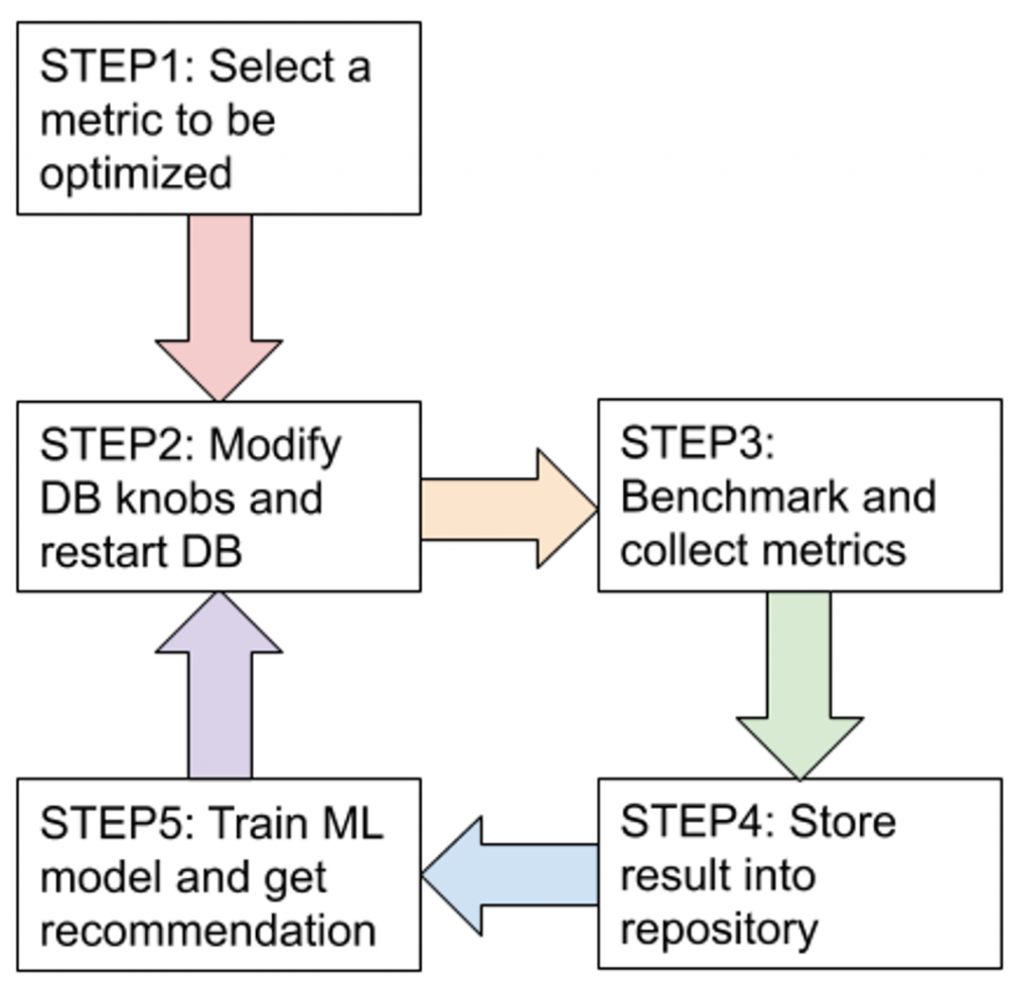
图一:整个过程会循环跑200个 round(用户可自定义),或者定义为直到结果收敛为止。
3、ML 模型
AutoTikv 使用了和 OtterTune 一样的高斯过程回归(Gaussian Process Regression,以下简称 GP)来推荐新的 knob,它是基于高斯分布的一种非参数模型。
在还没有利用机器学习模型对参数文件的效果进行预测的时候,OtterTune 使用的是随机采样的方式来收集初始数据。
当有足够的数据 (X,Y) 时,OtterTune 训练机器学习模型进行回归,即估计出函数 f:X→Y,表示对于参数文件 X,用 f(X) 来估计数据库延迟 Y 的值。如此,问题则变为寻找合适的 X,使 f(X) 的值尽量小。这样在 f 上面做梯度下降即可找出合适的 X[4]。
如图二所示,横坐标是两个参数:缓存大小和日志文件大小,纵坐标是数据库延迟(越低越好)。

图二:OtterTune 高斯过程回归模型
OtterTune 用高斯过程回归模型估计出了 f,即给定这两个参数值,估计出对应的数据库延迟。接着用梯度下降找到最合适的参数值,使延迟尽可能低。
高斯过程回归的好处:
- 和神经网络之类的方法相比,GP 属于无参数模型,算法计算量相对较低,而且在训练样本很少的情况下,GP 表现比神经网络算法(Neural Network ) 更好。
- 它能估计样本的分布情况,即 X 的均值 m(X) 和标准差 s(X)。若 X 周围的数据不多,则它被估计出的标准差 s(X) 会偏大(表示这个样本 X 和其他数据点的差异大)。直观的理解是若数据不多,则不确定性会大,体现在标准差偏大;反之,数据足够多时,不确定性减少,标准差会偏小。这个特性后面会用到。
但 GP 本身其实只能估计样本的分布,为了得到最终的预测值,我们需要把它应用到贝叶斯优化(Bayesian Optimization)中[5]。
贝叶斯优化算法大致可分为两步:
- 通过 GP 估计出函数的分布情况。
- 通过采集函数(Acquisition Function)指导下一步的采样(也就是给出推荐值)。
采集函数(Acquisition Function)的特性是在寻找新的推荐值的时候,能够进行平衡探索(Exploration)和利用(Exploitation)。
- Exploration:在目前数据量较少的未知区域探索新的点。
- Exploitation:对于数据量足够多的已知区域,利用这些数据训练模型进行估计,找出最优值。
在推荐的过程中,需要平衡上述两种指标。Exploitation 过多会导致结果陷入局部最优值(即重复推荐目前已知最好的点,但可能还有更好的点没被发现),而 Exploration 过多又会导致搜索效率太低(即一直在探索新区域,而没有对当前比较好的区域进行深入尝试)。而平衡二者的核心思想,是当数据足够多时,利用现有的数据推荐;当缺少数据时,在点最少的区域进行探索,探索最未知的区域能够提供最大的信息量。
贝叶斯优化的第二步就可以帮我们实现这一思想。前面提到, GP 可以帮我们估计 X 的均值 m(X) 和标准差 s(X),其中均值 m(X) 可以作为 Exploitation 的表征值,而标准差 s(X) 可以作为 Exploration 的表征值[6],这样就可以用贝叶斯优化方法来求解了。
使用置信区间上界(Upper Confidence Bound)作为采集函数。假设我们需要找 X 使 Y 值尽可能大,则 U(X) = m(X) + k*s(X),其中 k > 0 是可调的系数,我们只要找 X 使 U(X) 尽可能大即可。
- 若 U(X) 大,则可能 m(X) 大,也可能 s(X) 大。
- 若 s(X) 大,则说明 X 周围数据不多,需要探索未知区域新的点。
- 若 m(X) 大,说明估计的 Y 值均值大,则需要利用已知数据找到效果好的点。
注意:其中系数 k 影响着探索和利用的比例,即 k 越大,越鼓励探索新的区域。
在具体实现中,一开始随机生成若干个 candidate knobs,然后用上述模型计算出它们的 U(X),找出 U(X) 最大的那一个作为本次推荐的结果。
二、可行性分析
目前所有开源的自动调参工具实现原理基本上都是通过机器学习算法推荐配置参数,应用至数据库或者其他引擎上,在不同的工作负载模式下,不断收集 metric 信息,丰富训练模型,直至推荐出最优的配置,以此替代频繁的手动修改配置工作。
由调研可以发现,OtterTune 是通用模型框架,在业界许多场景都能应用,不仅能调优数据库的参数,还能够调优操作系统内核的参数,即只要能获取指标信息,大部分软件都可以用此模型进行调优。
同时可以借鉴 AutoTiKV 的测试代码,将目标 DB 替换为 Beaver_datanode,通过修改不同的配置,测试 baimi 数据集,收集 search 的性能数据,经过模型训练后不断推荐最优配置。
baimi 数据集,即 Apache 访问日志,总日志行数7078124,日志文件原始大小2374265761 Byte,测试 Beaver 和 ES 的搜索性能对比中用到的数据集。
AutoTiKV 代码分析:
1.pipeline.py
自动调参脚本入口,定义执行 round 数,自动推荐参数配置,修改配置文件并重启相关 DB,收集 metric 数据训练算法模型,以文件形式持久化保存对象。
2.settings.py
脚本参数配置,需要测试的 knobs、metrics 及 workload,数据库连接配置。需要优化的 metric(仅支持优化一项目标 metric)、ansible 和 deploy目录。
3.controller.py
knob 配置和 metric 获取相关函数,每一个需要修改的参数都需要在 knob_set 中定义,声明参数类型和取值范围,修改配置文件和重启数据库函数等。另外包括一些工作负载相关的 workload 函数。
4.datamodel.py
初始化数据设置,存放数据模型,每次测试的配置参数和获取到的指标数据都会存放在此模型中。
5.gpmodel.py
调用高斯过程回归类算法,传递并训练数据模型,根据算法推荐返回最佳配置参数,用于下轮测试。
注意:前十轮为随机生成 knob。
6.gpclass.py
即高斯过程回归算法。
7.showres.py
展示过往测试结果,将持久化保存的对象文件反序列化,调用 datamodel.py 函数中 GPDataSet 类输出测试结果。
三、具体实现
本着不重复造轮子的原则,本次测试决定使用 AutoTiKV 的算法代码,并修改其中关于数据库的代码,使其适用于 Beaver_datanode。
首先,TiKV 数据库使用的配置文件是 yaml 格式,而 Beaver 使用的是 flags 参数的形式(–max_concurrency_tasks_per_search=4),代码中使用的 ruamel.yaml 库文件并不适用于 Beaver。因此,对 controller.py 中 set_tikvyml 函数进行修改,以“=”为分隔符,读取旧配置文件并将参数以键值对形式写入字典中,对需要修改的配置项进行替换,最后把修改过后的配置参数写入到新配置文件中。
需要修改的配置参数应在 settings.py 中提前声明,更新 target_knob_set 列表中的参数,新增 wl_metrics 中 avgsearch 列表,并设置期望的 metric。在 controller.py 中补充参数的类型和取值范围,配置好 knob_set 和 metric_set。修改metric 数据获取函数,其中 read_search_latency() 函数是基于已经索引好的 baimi 数据集,测试某个场景的 search 性能。
参考了 Esrally 的性能压测代码[7],调用 Beaver_broker 的 API 接口,通过传递 pb 格式的搜索语句,来获取不同场景下的 latnecy。本次自动调参测试中,使用的搜索场景是从数据集中获取 apache.resp_len 字段的平均值,可以根据自己的实际环境自定义场景。因为每次得到的性能数据可能受到各种因素影响,或产生较大误差,为了降低误差值,搜索请求预热20次,压测100次,并计算前90th的平均值作为最终的 metric 数据。
settings.py 中需要修改的配置:

以下是 knob 和 metric 在 controller.py 中的声明样板:

Beaver 重启操作比较直接,使用 os.popen 管道命令直接在服务器上执行 kill 命令后更新配置文件重新启动,具体操作在 controller.py 文件的 restart_beaver_datanode() 函数中。在本次测试中,脚本直接运行在 Beaver 所运行的服务器中,首先需要在 settings.py 文件中声明 Beaver_datanode 的启动命令和各项配置文件路径,指定配置文件临时存放路径。使用 “ps -ef|grep beaver_datanode” 即可查看 Beaver_datanode 的启动命令。
具体配置示例如下:

四测试结果
1、knobs
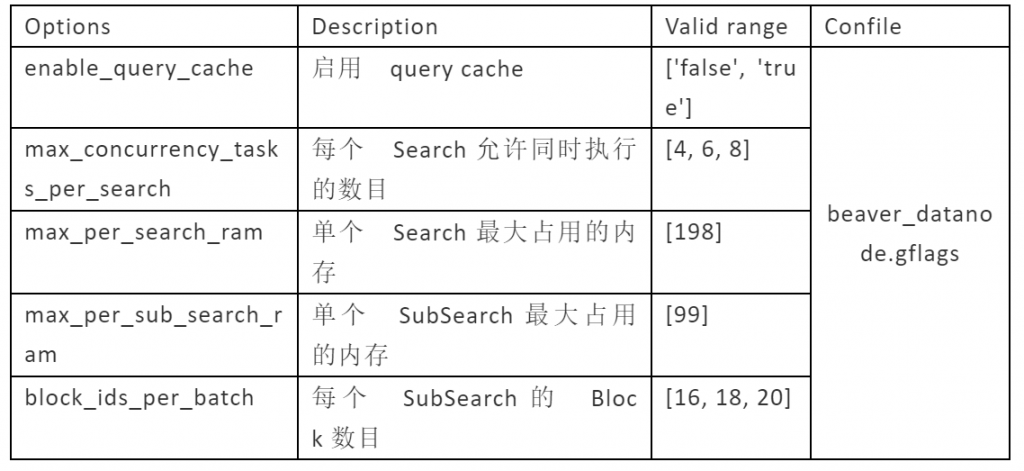
此次测试主要测试了以下配置项:
2、metrics
我们选择了如下几个 metrics 作为优化指标。
- search_latency:搜索延迟(ms)
- compaction_mem:占用内存比例(%)
- compaction_cpu:占用 CPU 比例(%)
注意:knobs 和 metrics 均在 contorller.py 文件中定义。
3、脚本具体使用步骤
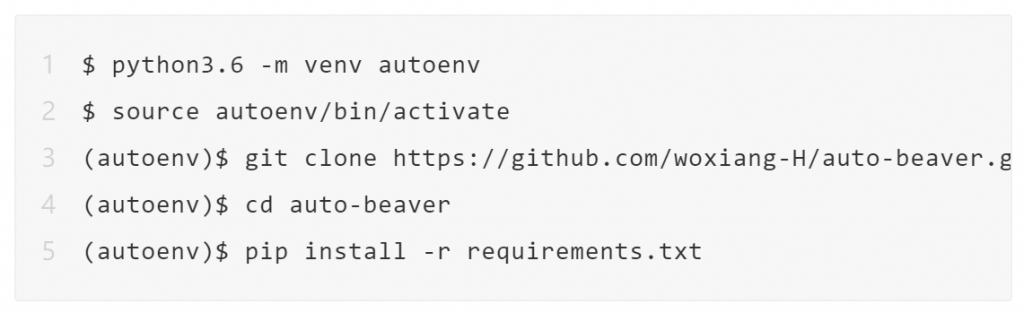
安装 Python 3.6

安装虚拟环境,切换到 Python 3.6 环境,下载自动化调参工具,并使用 pip 安装相关依赖包
按照之前具体实现中提到的需要修改的配置,修改 auto-beaver 下 settings.py 文件。
调整好 settings.py 之后,执行 python pipeline.py等待结果收敛,查看推荐配置

可以看到最佳推荐配置为[0. 0. 0. 0. 0.]和[0. 1. 0. 0. 1.](此数字含义为 list 中的下标索引),具体配置参数如下。

或者

结果显示,适当提高 search 并发数,或提高 SubSearch 的 block 数会优化search 性能。
五、存在的问题
通过修改相关代码,目前自动调参工具能正常运行,但依然存在不足。本次测试方案利用事前存储好的索引 baimi 数据集,仅测试影响 search 性能的参数,因此可修改的配置项也相对较少。虽然舍弃了 AutoTiKV 的 workload,但代码依然保留此功能,待后续有针对 Beaver 的工作负载方案之后,再添加相关 workload。此外 Beaver_datanode 的重启方式也并不优雅,有待提升。
后续可优化:
- 增加不同的 workload 模式,测试 index 性能和 search 性能(需要 Beaver支持新的 index 方式),同时测试 index 相关的配置参数。
- 优雅地重启 Beaver_datanode。
- 目前重启等待 Beaver_datanode 可用的 wait 时间为200s,在实际运行的 Beaver_datanode 中,索引恢复时间相对较长,需根据不同环境灵活变化。
- 指标数据获取的准确度,会受到网络等因素的影响,有一定的波动。
【参考文献】
[1] OtterTune. https://github.com/cmu-db/ottertune
[2] AutoTiKV. https://github.com/tikv/auto-tikv
[3] Automatic Database Management System Tuning Through Large-scale Machine Learning. https://www.cs.cmu.edu/~ggordon/van-aken-etal-parameters.pdf
[4] https://mp.weixin.qq.com/s/y8VIieK0LO37SjRRyPhtrw
[5] https://blog.csdn.net/Leon_winter/article/details/86604553
[6] https://blog.csdn.net/a769096214/article/details/80920304
[7] Esrally. https://github.com/elastic/rally
拓展内容
- https://www.cnblogs.com/pdev/p/11318880.html
- https://gitee.com/opengauss/openGauss-server/tree/master/src/gausskernel/dbmind/tools
日志易
日志易专注于机器大数据平台、服务和解决方案,致力于帮助各行业用户挖掘和利用机器数据价值,提升数字化运营质量,轻松应对IT及业务挑战。公司推出日志易平台、数据工厂、智能运维AIOps、安全分析平台、大屏展示等系列产品,一站式解决机器数据采集、清洗、存储、搜索、分析、可视化等需求,帮助企业轻松实现查询统计、业务关联分析、监控告警、安全信息与事件管理(SIEM)、用户行为分析(UBA)、智能运维等应用场景。