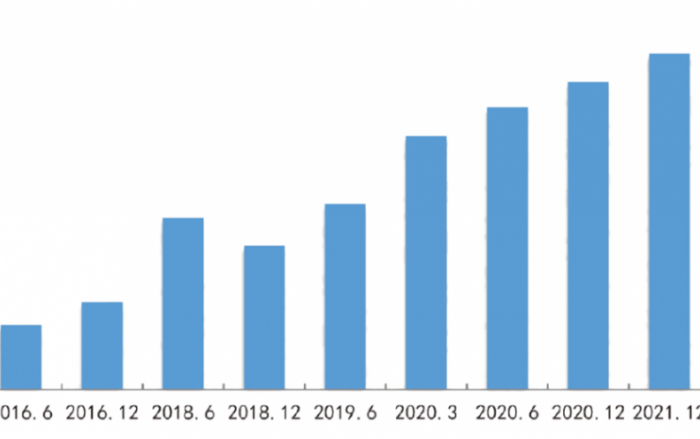
数字化进程中,现代组织每天产生和处理的数据量在以惊人的速度增长着,各行各业如交通、财政、医疗、社交媒体等业务应用的多样化,造成了数据的庞杂和无序,为组织的数据资产安全带来了隐患。这种情况下,梳理和分析敏感数据成为了组织保护数据资产安全的首要问题。与此同时,欧盟的通用数据保护条例GDPR(General Data Protection Regulation)、美国的金融现代法案GLBA(Graham-Leach-Bailey Act)、健康保险携带和责任法案HIPAA(Health Insurance Portability and Accountability Act)等国际信息保护法案都对敏感数据的保护提出了明确需求。高效的数据分类分级工具能够按照数据的敏感程度对组织内部数据进行分类识别,有助于提高数据安全防护的针对性和有效性,同时也可以满足组织数据的合规性需求,因此成为数据安全领域的关注焦点。
国际上对于数据分类分级一般统称为数据分类(Data Classification),用来描述按相关类别组织数据的过程。在此基础上根据需要对分类的级别(Classification Levels)和类别(Classification Categories)进行分别描述,以便可以更有效地使用和保护数据,并使数据更易于定位和检索。
Netwrix是美国一家提供信息安全与治理技术的网络安全公司,为用户提供以数据为中心的安全服务,被评为2020年Gartner文件分析软件市场指南“代表性供应商”、2020年Gartner Peer Insight文件分析软件“客户之选”。自2013年起每年均入榜德勤北美高科技发展500强企业,2019年其敏感数据保护解决方案带来178%的业绩增长率。
Netwrix的数据分类产品在2020年Gartner Peer Insight报告中被评为“最好用和最重要的数据分类软件”、“100%推荐率和易用性高的软件”。本文将主要介绍Netwrix数据分类平台的主要功能、运行环境配置以及具体功能组件,为洞察国外厂商数据分类相关工具的实现思路提供参考。
一. Netwrix数据分类平台功能和流程概述
Netwrix数据分类平台通过使用数据发现和分类工具(Data Discovery and Classification Tool,简称DDC)实现分类功能。工具自动识别不同应用程序的结构化和非结构化数据,并结合预定义的分类法对文件进行分类,基于分类结果展示数据的分布状态统计。其主要特点为:
无需部署客户端,使用基于WEB的管理控制台执行数据分类操作;通过HTTP协议和第三方应用API接口定位数据源;支持预定义的分类规则,实现对受GDPR、GLBA、HIPAA和其他监管标准保护数据的识别,也可以通过自定义分类规则查询识别其他数据;使用逻辑化和持续化的全文本索引模式,配合使用机器学习算法、语义分析自动查询文件内容;并为每种分类规则设置关联度得分,得分值可依据数据分类结果实时调整,用以调整文件匹配的范围;支持包括英语、德语、法语、汉语、日语、韩语等50余种语言的数据分类。
- 平台主要功能
Netwrix数据分类平台主要包括三个功能:数据采集、数据分类和数据分类结果的可视化呈现。上述功能通过基于WEB的管理控制台(Management Console)贯穿为一体,实现对分类过程的操作配置。
- 数据采集
运行在数据分类服务器(Data Classification Server)上的数据分类采集服务(Data Classification Collector Service),采集数据源(Data Source)的文档后,将文档转换为纯文本,并形成文件元数据(Metadata)存储于数据分类SQL数据库(Data Classification SQL Database)。数据分类索引服务(Data Classification Index Service)基于收集的文档内容和元数据,创建全文本查询索引(Full-text Search Index),并将其存储至索引库(Data Classification Index)。
- 数据分类
数据分类服务(Data Classification Classifier Service)根据Netwrix预定义的第三方分类法(Taxonomies)和用户自定义的分类法,对文件内容匹配后分类,最终将分类结果存储于数据分类采集数据库(Data Classification Collector Database)中。
- 分类结果展示
通过查看管理控制台上的数据源及分类规则详细信息、统计审计报告如文件分布地图等功能,展示数据分类结果。

图1 Netwrix数据分类流程图
- 平台运行环境
根据实际数据分类需求场景,其运行环境基础配置如下:
- 数据分类服务器
- 硬件环境:多核CPU,8G以上内存;
- 软件环境:操作系统Server2012R2以上版本,配置服务器(IIS)角色。此外,需将.CSE格式的索引文件添加至杀毒软件的白名单中,避免被当作恶意文件删除。
- 数据分类SQL数据库
该数据库主要用于存储元数据的SQL Server数据库。
- 软件环境:2008SP2以上版本数据库(推荐2016SP2),Visual Studio2015以上版本。如果通过SQL Server管理工具配置该数据库,需将数据库的恢复模式设置为简单模式,并设置主数据库.mdf文件的自动增长值和最大值。
- 索引库
此索引库是用来存储纯文本索引文件(.CSE格式)的磁盘空间,空间大小为计划索引文件总大小的35%。例如当前有45GB的文件需分类,则索引文件所需磁盘空间应至少为15GB。
- 数据分类规模
Netwrix对数据规模的定义为:分类文件数量小于50万份,即为小型规模;800万左右为中等规模;3200万左右为大型规模;大于3200万则为超大规模。
- 数据分类性能
数据分类性能取决于数据规模,当分类数据规模达到大型和超大规模时,建议使用分布式服务器集群部署模式来均衡主服务器的负载。集群中的每个数据分类服务器共享同一个元数据库,各自存储索引文件,彼此之间相互通信。
一. 平台主要组件功能解析
- 数据采集
数据源是需采集和分类的数据存储库。通过管理控制台的数据源内容配置功能,实现对需采集数据源的添加和管理,添加后可查看数据采集结果。
Netwrix支持分类的数据源有:Windows文件系统、Windows Server系列服务器、Linux文件系统(SMB/CIFS/NFS)、Office 365、数据库、Outlook(2010以上版本)、DropBox、Exchange服务器/邮箱、Google Drive、SharePoint等。在数据采集阶段,除了选择需采集的数据源类型,还需针对每种数据源配置相应的采集选项,以便于更精细化地定位。此处以常用的两种数据源——数据库和文件系统为例,描述添加数据源功能。
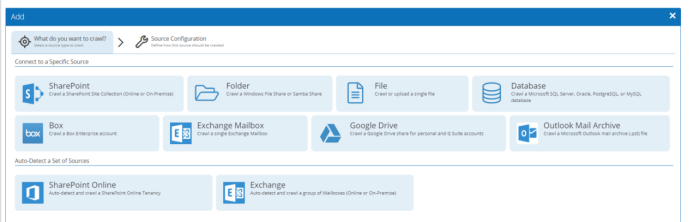
图2 选择需采集的数据源类型
- 数据库
Netwrix支持对SQL Server(2008以上版本)、Oracle、PostgreSQL、EMC等主流数据库内容的采集及分类。采集前需要先设置数据库访问用户名(如Windows服务或IIS程序池用户)或连接信息。数据库连接创建成功后,数据分类采集服务即可将采集到的内容智能映射为元数据。数据库内容采集的主要配置项如下:

图3 数据库采集配置项
- 数据库类型。从SQLServer、Oracle、MySQL、PostgreSQL等选项中选取所需采集的数据库类型。
- 数据库服务器信息。设置采集目标数据库的服务器地址、具体数据库名称、登录用户名和身份认证方式。
- OCR处理模式。Netwrix可以通过OCR模式采集数据库文件中的图片内容,可从“禁用/默认路径/标准质量/增强质量”4种模式中选择。
- 数据库采集范围。设置需采集内容的数据库表、列的范围。
- 文件系统
Netwrix支持对Windows文件系统和Linux文件系统的内容采集,其主要配置项如下:
- 文件(夹)路径。设置需采集内容的文件(夹)路径。
- 文件夹级别。设置采集文件夹深度,可以选择是否包含子文件夹、是否采集所有子文件夹,以及子文件夹深度的范围(2-99级)。
- 文件夹访问信息。设置访问文件夹所需的系统帐户和密码,以及是否允许匿名访问文件目录;
- 重新索引周期。当源文件发生变更(增加/修改)后,Netwrix分类会定期更新索引,默认更新周期为7天。
- 文件类型。设置需采集的文件类型。
- 是否采集相同内容的副本文件,以及采集文件的优先级。
- 查看数据源采集结果
数据采集流程自动对数据源进行采集、格式转换和创建索引的处理操作后,即可在管理控制台上查看数据源采集结果,包括:数据源类型、数据源文件位置、数据源采集状态、数据源索引创建状态、数据源采集文件数量及总大小。
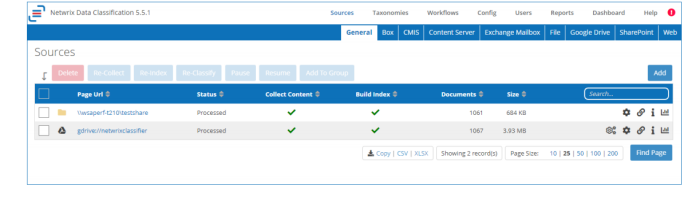
图4 数据源采集结果
- 数据分类
Netwrix数据分类工具提供预定义分类法,这些分类法包括数百个现成的分类规则。每种分类法包含一系列术语(term),术语又由一系列配置规则(configuration clue)定义。通过使用规则与文件内容进行匹配,最终定位源文件的所属分类。
- 分类法
Netwrix数据分类平台所提供的预定义分类法共8种,其中4种核心分类法覆盖了个人、金融、医疗等领域,包括:财务信息(Financial Records)、PII(Personal Identifiable Information,个人可识别信息)、第三方支付行业数据安全标准(Payment Card Industry Data Security Standard,PCI DSS)、患者健康信息(Patient Health Information,PHI),余下4种衍生于核心分类法,用于满足部分特定的合规性要求,称为衍生分类法,包括:GDPR(通用数据保护条例)、GDPR第九章中涉及的个人信息特殊类别、GLBA(金融现代法案)、HIPAA(医疗保险可携性和责任法案)。除了上述预定义分类法外,用户也可以添加自定义分类法。
- 分类规则
分类规则通过复合词精确/模糊匹配、区分大小写、单词发音、正则表达式、语种类型匹配等11种匹配方式,查询文件内容后对其分类。此外,用户也可以添加自定义分类规则,添加时可设置规则的分数,代表其与分类特征的关联度。分数越高,则关联度越高,此项规则可用于对文件进行分类的概率越大。
分类规则用于描述文档中发现的语言,使得文档归属于特定的主题。Netwrix提供预定义分类规则用于查询文件内容,这些规则涵盖了如英语、法语、德语、西班牙语等多语种的个人可识别信息(姓名、家庭住址等),以及英国、新加坡、南非等多个国家的识别码和登记码。
- 分类标签
Netwrix支持将分类标签写入被采集数据的属性中。具体操作方式为:在管理控制台上,将分类标签写入到指定数据源的属性中。分类标签可采用[分类名称|分类ID]的格式呈现。
例如:农业分类法中有农场(ID为11)和生产(ID为32)两个子分类。当同时包含农业和生产的文件分类完成后,分类标签即写入该文件的属性中,即文件属性增加项——属性名称农业,属性值[农业|11;生产|32]。
- 数据分类结果展示
数据分类结束后,即可在管理控制台通过多种方式查看分类结果。
- 通过数据源查看
选择某项数据源,即可查看已采集的数据信息,包括:文件名称、路径、分类状态、匹配的分类等内容。
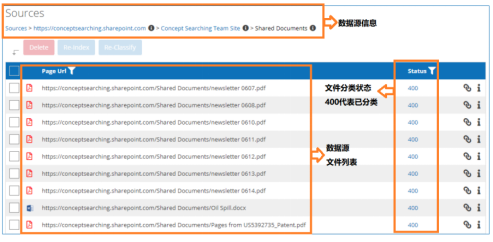
图5 通过数据源查看文件分类结果
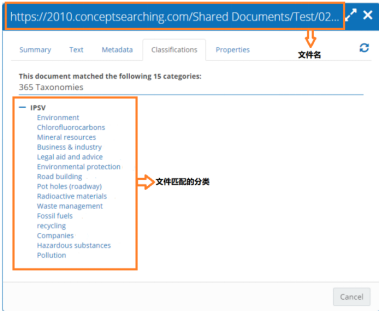
图6 查看每个文件对应的分类
- 通过规则查看
选择分类法及其子节点中的术语,即可查看该术语对应的规则信息,包括:规则类型、规则名称、规则的分数。选择每种规则,即可查看与之匹配的文件数量。
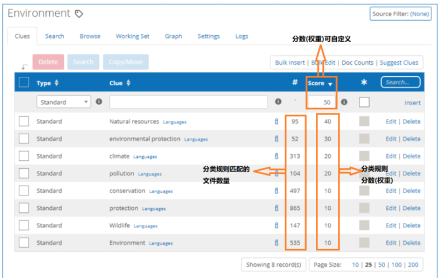
图7 通过规则查看分类结果
- 文件分析报告(Data Analysis Report)
可在Netwrix管理控制台上查看数据分析报告,对报告中的数据进行筛选和细化,以查询包含文件按照分类结果的分布状态。常用的报告有三种:文件分布地图(按分类和数据源分组统计),以及最近一周分类标签分配情况。
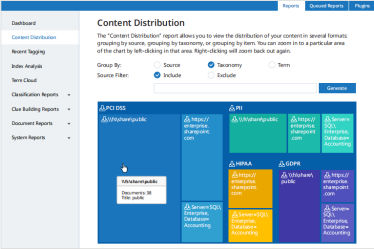
图8 文件分布地图-按分类法分组统计

图9 文件分布地图-按数据源分组统计

图10 最近7天分类标签分配情况
小结
Netwrix作为全球500余家公司的数据安全治理供应商,实际数据分类、数据审计、数据安全功能远不止这些。Netwrix的数据分类工具作为数据安全的基础,提供了诸多参考方向,例如:无需单独部署客户端,使用一套服务器、一个WEB管理控制台的轻量化部署,即可完成数据分类全过程;可基于不同种类的分类数据源配置相应的分类配置项,为更精确的定位数据源提供支撑;使用预定义的数据合规分类法及其规则,满足国外对个人隐私数据识别的主流需求;使用多维度的象限统计图表,更直观地查看数据的分布情况。除此之外,Netwrix的数据审计和数据安全功能,能够提供以数据分类为基石、以用户实体行为分析UEBA(User and Entity Behavior Analytics)为核心的数据安全审计功能,最终形成数据防护流程体系。鉴于此,其数据安全治理理念仍值得深度解读。
参考网址:
- https://www.netwrix.com/data_classification_software.html
- https://www.netwrix.com/auditor.html
- https://www.netwrix.com/download/Datasheets/Datasheet_-_Netwrix_Data_Classification.pd
- https://www.netwrix.com/download/documents/Netwrix_Data_Classification_for_Box.pdf
- https://www.netwrix.com/download/documents/Netwrix_Data_Classification_Installation_Guide.pdf
申明:本文系厂商投稿收录,所涉观点不代表安全牛立场!
中孚信息
中孚信息成立于2002年,专业从事信息安全产品的研发、销售并提供整体解决方案。公司拥有齐全的业务运营资质和产品质量体系和多个国家级、省级创新平台。中孚信息积极推进国家网络安全强国战略,着力打造信息安全、人工智能和大数据技术深度融合的特色优势,巩固和夯实在网络安全领域的优势地位。 中孚信息为党的十九大、上合峰会等国家重大会议、赛事保驾护航。未来,中孚信息将继续打造开放共赢生态链,共同推动国家信息安全事业的发展。