随着数据的海量增长和数据潜在价值的不断提升,数据已经成为最重要的资产。据国际数据公司IDC预测,到2025年,中国数据圈在2025年增至48.6ZB字节,占全球27.8%,成为最大数据圈。但社会各界对数据的管理还不够重视,普遍存在数据质量低、数据孤岛、数据安全管理不到位、数据流通共享不畅的问题成为困扰大数据往前发展的障碍。数据拥有者出于数据安全保密的顾虑而不愿共享数据,使得不同企业、不同机构间难以利用对方的数据进行联合分析或建模。那么如何平衡大数据共享与隐私保护,打破数据烟囱与信息孤岛,挖掘数据的真正价值?
大数据时代隐私数据面临的威胁
在大数据环境中,隐私信息贯穿于数据的采集、传输、存储、分析以及应用的全过程。大数据生命周期各个阶段面临的风险如下图所示。
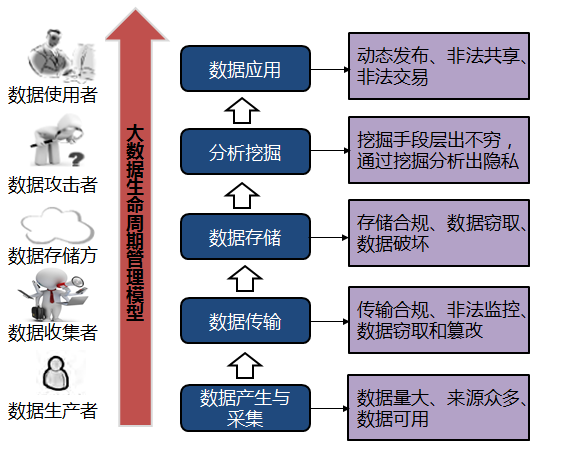
大数据时代隐私数据保护技术
大数据隐私保护访问控制技术主要包括基于角色挖掘、基于风险访问控制、基于半/非结构化数据的访问控制、基于隐私保护的访问控制、基于世系数据相关的访问控制、基于密码学的访问控制技术等技术。
对于含有敏感信息的大数据来说,将其加密后存储在云端能够保护用户的隐私,然而若使用传统的DES、AES等对称加密手段,虽能保证对存储的大数据隐私信息的加解密速度,但其密钥管理过程较为复杂,难以适用于有着大量用户的大数据存储系统。同态加密算法可以允许人们对密文进行特定的运算,而其运算结果解密后与用明文进行相同运算所得的结果一致。全同态加密算法则能实现对明文所进行的任何运算,都可以转化为对相应密文进行恰当运算后的解密结果。将同态加密算法用于大数据隐私存储保护,可以有效避免存储的加密数据在进行分布式处理时的加解密过程,将全同态加密技术和MapReduce编程模型进行结合,通过在reduce模块之前,增加一个在密文状态下进行计算的转换模块,使得经过全同态加密后的文件可以在不解密的情况下进行MapReduce运算,从而能够大大优化存储的大数据隐私信息的运算效率。
3.大数据的动态匿名技术
针对大数据的持续更新特性,提出了基于动态数据集的匿名策略,这些匿名策略不但可以保证每一次发布的数据都能满足某种匿名标准,攻击者也将无法联合历史数据进行分析与推理。这些技术包括支持新增的数据重发布匿名技术、m-invariance匿名技术、基于角色构成的匿名]等支持数据动态更新匿名保护的策略。
4.大数据的匿名并行化处理
分布式多线程是主流的解决思路,一类实现方案是利用特定的分布式计算框架实施通常的匿名策略,利用Map Reduce分布式计算模型成功地实现了大数据集上可扩展的匿名系统;另一类实现方案是将匿名算法并行化,使用多线程技术加速匿名算法的计算效率,从而节省了大数据中的匿名并行化处理的计算时间。
5.大数据隐私保护挖掘技术
隐私保护数据挖掘,即在保护隐私前提下的数据挖掘,其主要关注点有两个:一是对原始数据集进行必要的修改,使得数据接收者不能侵犯他人隐私;二是保护产生模式,限制对大数据中敏感知识的挖掘。主要包括基于关联规则、基于分类和基于聚类的隐私数据挖掘技术。
基于关联规则的隐私保护主要有两类方法:第一类是变换(distortion),即修改支持敏感规则的数据,使得规则的支持度和置信度小于一定的阈值而实现规则的隐藏;第二类是隐藏(blocking),该类方法不修改数据,而是对生成敏感规则的频繁项集进行隐藏。分类方法的结果通常可以发现数据集中的隐私敏感信息,因此需要对敏感的分类结果信息进行保护。这类方法的目标是在降低敏感信息分类准确度的同时,不影响其他应用的性能。与分类结果的隐私保护类似,保护聚类的隐私敏感结果也是当前研究的重要内容之一。对发布的数据采用平移、翻转等几何变换的方法进行变换,以保护聚类结果的隐私内容。此方法首先是对原始数据进行几何变换,以对敏感信息进行隐藏,然后是聚类过程,经过几何变换后的数据可以直接应用传统的聚类算法(如K近邻)进行聚类,在聚类准确度和保护隐私方面达到了较好的平衡。
隐私数据保护解决方案
针对大数据环境下用户面临的安全威胁,需要面向动态安全需求的、自适应的隐私保护解决方案。

- 自适应的隐私感知
通过安全需求工程的方法,把握不同应用、不同实体的需求,自适应的部署相关安全策略,合理地组合多种隐私保护手段,为数据的处理、存储、发布和使用提供全方位、多维度的协同保护。针对数据处理场景的多样性进行建模,自适应的引入网络编码、访问控制、及基于密文的数据处理等多种技术,为大数据的迁移、保存和整理提供涉及用户隐私信息的保护。
- 敏感信息智能清洗
在大数据发布过程中实现面向动态需求变化的敏感信息智能清洗,对大数据应用实例,如科学协同计算、消费者行为调查等,进行隐私保护需求建模。根据建模结果,确定所涉及数据的隐私敏感度和数据可用度。并在发布数据之前,通过考察既往发布数据确定攻击者能力,并根据博弈论给出的攻击演化趋势,确定最终要发布的数据。
- 隐私信息泄露的风险评估
按照CORAS工程的风险评估框架,建立大数据隐私信息泄露的风险评估模型。应用信息安全的风险评估理论,从准备和风险识别两个阶段出发,研究定性和定量地评估大数据隐私保护模型信息泄露的风险指数。
一次次数据泄露事件付出的代价,让我们明白了隐私数据保护的重要性,也感受到了企业数据安全保护的紧迫性,确保数据安全才能实现发展,大数据才能发挥出更大经济效能,数据安全这场攻防战永无止境。
申明:本文系厂商投稿收录,所涉观点不代表安全牛立场!
世平信息
杭州世平信息科技有限公司(简称“世平信息”)成立于2010年,致力于智能化数据管理与应用的深入开拓和持续创新,为用户提供数据安全、数据治理、数据共享和数据利用解决方案,帮助用户提升数据资产风险管控与数据价值安全利用能力。

