随着互联网技术的发展与普及,企业网站每天接收各种正常或者非正常请求。如果不能有效识别非正常请求并执行适当的防护策略进行控制,则将影响网站的正常运行,甚至造成企业的经济损失。
面对每日产生的TB级别、条目达百亿级别的海量日志,如何挖掘其中非正常访问的行为特征,是我们一直不断探索的方向。
上文基于对海量日志的挖掘和关联分析,探索了针对恶意爬虫的特定访问行为,通过请求UA、IP、时间粒度三个维度进行特征提取和识别标记来判定恶意爬虫IP。 本文将继续探索针对扫描行为IP进行特征识别和标记。
Web扫描行为的目标是检测网站是否存在潜在有危险的Web漏洞,扫描行为可能来自Web攻击者,也可能来自监管单位。由于这类扫描行为会在短时间内进行大量请求,增加网站不必要的资源消耗和压力,对于网站来说,存在网站管理人员操作错误导致网站出现Web漏洞进而被有心者利用的情况。因此,对于网站来说,如果能够主动识别和拦截扫描行为,能够极大降低网站漏洞被发现概率和被利用风险,同时还能够降低被监管单位通报的风险。
目前网络上存在各种开源、商业化Web扫描工具,以及使用脚本扫描的网络安全研究者。一般扫描行为主要分为两种:一种是先爬取网站再通过字典发现漏洞,一种是直接基于字典发现漏洞。本文主要探索针对基于字典进行扫描的特征识别和IP标记。
对任一网站来说,其使用的Web服务端开发语言、开发框架是确定唯一的,比如JSP/ASP/PHP;使用的Web服务器、中间件也是确定唯一的,比如IIS/Apache/Nginx。无论是Web开发框架还是Web服务器、中间件,已发布的版本中均会存在一些已知或未知的可被利用的Web漏洞。
扫描行为会通过内置Web开发框架或Web服务器、中间件的漏洞列表,对网站进行测试和漏洞发现(如图1所示)。同时,扫描行为还会通过收集的各种漏洞,如敏感目录或者敏感文件(如.bak .sql),对网站进行漏洞测试和发现(如图2所示)。通过历史日志分析发现,每个网站使用的资源文件类型都是确定的(如图3所示)。

图1 某IP针对Web服务器扫描行为

图2 某IP针对敏感文件的扫描行为

图3 Web网站的资源文件类型
基于上述分析,我们可以发现网站一般具有以下特征:
- 具有特定且唯一的Web语言相关的资源文件(如.php .asp .jsp)
- 资源文件列表是确定的
- 特殊敏感的资源文件一般是不需要对外访问的(如.sql .svn)
基于以上特征,我们研究了一种针对Web扫描行为进行识别和标记的方法,基本过程如下:
- 通过累积的历史日志、防护日志以及收集的各类扫描器特征,按照资源文件类型归类划分危险等级(高、中、低危);
- 通过历史日志分析,获取每个网站专属的正常响应的资源文件列表;
- 针对每个IP访问的资源文件进行实时统计分析;
- 根据上述特征1,如果IP同时访问了多个Web语言相关的资源文件,比如既访问了.php又访问了.jsp,则认为当前IP有较高的扫描行为嫌疑;
- 根据上述特征2、3,结合各个资源的风险等级,如果IP访问的各个风险等级的资源文件达到系统内置的一些阈值条件,则认为当前IP有较高的扫描行为嫌疑,如IP访问了.sql .svn这类高危资源文件,则认为当前IP有扫描嫌疑。
通过实时标记具有上述扫描行为特征的IP发现,系统平台上每分钟都有发生针对部分网站的扫描行为。系统已累计标记20W+的具有扫描行为的IP,为验证标记IP的行为,通过人工日志审计,确定标记的IP确有扫描行为,同时用标记IP在IPIP.net上查询,确认对应IP的风控信息为非正常IP(如图4所示)。

图4-1 标记的扫描行为IP
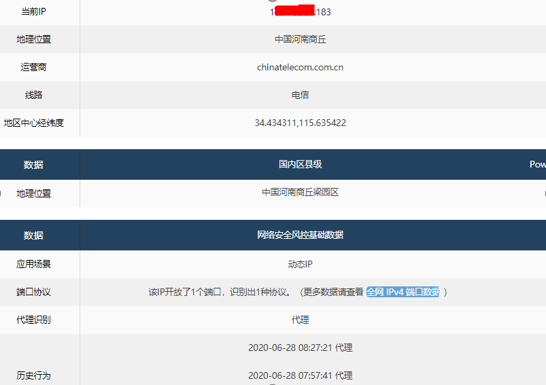
图4-1 标记的扫描行为IP
对该类扫描特征行为IP的防护建议是:拦截。
本文通过日志分析,基于网站特征和扫描行为特征研究了一种基于请求资源文件特征识别扫描行为的方法。当然,本文列举的方法并非能够识别所有扫描行为,对于其他特征的扫描行为,我们仍在持续分析和总结,以便为用户提供更好的防扫描服务。
申明:本文系厂商投稿收录,所涉观点不代表安全牛立场!
云盾智慧
云盾智慧安全科技有限公司专注于网络安全产品、服务和解决方案的创新与研发,是专门为政府、企事业单位等各行各业机构提供企业级网络安全产品、服务、解决方案的专业安全公司。 云盾智慧当前可提供Web安全解决方案、网络安全态势感知解决方案以及网络安全服务。
