长亭新品牧云(CloudWalker)服务器安全平台开源在即。
《牧云开源的背后》(点击进入)
长亭研发攻城狮们在对开源产品持续优化,期待用更智能、高效的算法赋予当前CWPP类产品更多创新。今日奉出研发手记一枚抛砖引玉,聊一下市场上比较关心的Webshell监控检测的一些方法策略。
Webshell也在升级,混淆、变形等问题都会造成误报,是否存在技术创新对当前检测方法进行有益的补充?
产品特色
目前大多 Webshell 检测存在检测维度单一,检测时间较长,检测手段需要执行入侵等产品策略问题,某些知名 Webshell 检测产品的召回率也远不能达到实际需求的效果,牧云Webshell 监控检测针对这些做了改进,尝试呈现全新的技术解决方案。
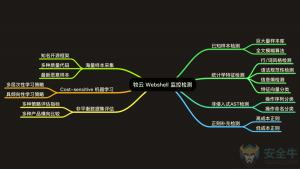
- 在检测维度上,牧云采用样本模糊匹配、统计特征检测、AST 语法检测、正则补充检测的多维度检测方案。
- 检测过程完全在主机进行,无网络传输和云端请求的时间成本。
- 检测方案覆盖了非入侵式检测中绝大多数可以使用的数据模型。
- 检测过程无代码执行,避免沙箱逃逸,也无需更改原有服务架构和路由策略,使得配置更为方便。
研发思路
Webshell 检测在的很长一段历史时间内,是基于正则匹配的,这也是 Webshell 绕过极为便捷的原因。即便在普遍部署云服务的今天,高强度编码和加密过的 Webshell 脚本也是各种挖矿脚本的元凶。牧云在研发开始前,就试图以一种全新的检测方式和检测层次,丰富现有的技术方案。
研发初期我们尝试站在安全从业者视角观察问题:对整个样本文件概览之后,能否快速地得到一个结论:这个像是/不像是一个正常文件?我们也希望牧云可以像人一样,在进行 AST 分析之前,通过“看一眼”的方式,得到一个基本判断。
检测策略的核心是使用 SVM 作为分类器。作为安全防护产品,防护过程中出现漏网之鱼比过度保护对客户的价值损失更大。牧云要实现的不是一个普通的机器学习分类器,而是一个对某一分类成本敏感(Cost-sensitive)的分类器。针对多个检测维度,牧云通过两个层次的机器学习设计使得数据分析更为准确。
阶段至此,没有进行任何诸如正则的精确的匹配,这种智能化的监控检测策略已经使得很多常见“大马”无法绕过牧云的检测。
这是机器学习的优势,也是它的劣势。针对特殊构造的小型文件以及一些已知的 Webshell 样本,牧云还不能进行宏观上的预测。于是,我们基于 GitHub 上大量开源 Webshell 样本文件,采用了一套模糊 Hash 和模糊正则的策略,将一些上层的漏网之鱼一网打尽。
此外,考虑到客户的主机环境不可能像训练中的数据集一样有大量 Webshell 文件混杂在其中,尝尝仅存在千分之一甚至万分之一的恶意文件,在研发后期的产品评估过程中,我们尽可能按不同编码层次水平抽样,创造一个非平衡数据集的评估环境。
经过系列数据集测试和部分知名产品进行对比,牧云在 Webshell 监控监测方面显示出了较大的优势。
策略优势
类人化思考
牧云使用类人化的思考方式对样例文件进行基本判断。
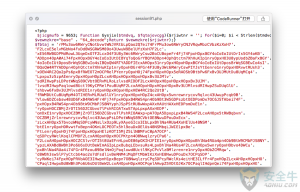
作为技术专业人员,身为人类的我们在看到上图的瞬间可以基本判断这个文件这不是一个正常的 PHP 文件:因为代码可读性极低、奇特的命名方式、拼接方式、编码方式,以及极为不正常的一个超长字符串。这些都是可以通过统计学得到的相关指标:字和行长度的分布规律、全文中符号的和<tag>标签的占比、文件的信息熵值等等。将这些指标进一步细化到牧云的检测算法后,初步检测显示牧云可以根据统计学指标粗略的指出:这是一个不正常的文件。
AST 的特征提取
牧云针对每一个测试样本的 AST 特征,进行了两个维度的匹配:操作序列和操作命名。
对于已生成的 AST,牧云通过 BFS 方式遍历非叶节点,将每个非叶节点和它的子节点形成一个元组,称之为操作序列。在得到操作序列后,牧云会对操作序列内部重复迭代的子序列进行多次清洗,最终得到一套最为简短并保留全部操作特征的操作序列,并将选取出现次数较多的序列作为特征,通过 SVM 训练分类,得到操作序列的数据特征。
另一维度,牧云在 AST 中提取全部的字符串样本,实际为 AST 中所有的 name,即操作命名。AST 中的操作命名样本比文本文件中字符串更能体现语法层次的特征,牧云再将操作命名元组通过朴素贝叶斯分类器进行分类,获取操作命名的数据特征。
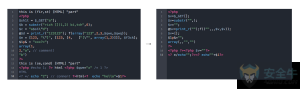
Cost-sensitive 分类器
Cost-sensitive 是机器学习在应用的过程中的一个重要难题,通常我们会使用下面的例子来解释这个问题。
假设银行会通过一个机器学习分类器,预测贷款申请人的信用状况,判断是否应该接受贷款申请。这是一个典型的 2-class 的分类问题。从机器学习算法的角度考虑,最优解应该是将正确分类率提升到最高,这个值可以通过Accuracy=(TP+TN)/(TP+TN+FP+TN)得出。而在实际应用中,将贷款发放给失信者造成的损失比拒绝将贷款发放给守信者的损失要高得多,最优解应该保证分类结果给银行造成的损失最小。
在 Webshell 检测的过程中,我们面临同样的问题:漏报会比误报对客户造成更大的损失,同时误报也会对用户造成很大困扰。在训练过程中,我们在收集了大量正负样本的基础上,通过 Rescaling 方法,更改了交叉验证中每一 fold 的正反数据比例,通过对右图的 cost matrix 不断修正,达到最佳的 cost-sensitive 分类训练效果。
![]()
模糊 Hash 和模糊正则
模糊 Hash 和模糊正则策略是作为以上策略的补充存在的。
模糊 Hash 通过经典的 ssdeep 将大于 4096bit 的样本与已知样本 Hash 进行比对。ssdeep 将文件以特定算法进行分片,采用滚动 Hash 算法取得所有 Hash 值连接,得到不定长度的 Hash 值。在比较时,两个文本进行同样的模糊 Hash 操作,并通过加权编辑距离(Weighted Edit Distance)与两文本长度和的比值得到相似度。
模糊正则策略是在可配置的正则列表中添加部分正则表达式和正则表达式组。模糊正则在正则匹配前,根据一套词法分析规则,将文件标记化(Tokenization)之后再进行正则匹配。
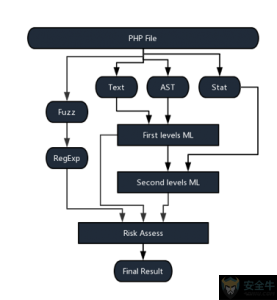
策略流程
如研发思路所述,整个策略的运行流程完全不涉及对样本 PHP 文件的运行和操作,做到真正意义上的非侵入式监控检测。
策略流程大致包括以下几个步骤:
3. 根据 Step2 的两个特征进行分类,得到两个分类值
4. 将统计学特征值和 Step3 的两个分类值进行第二层分类
5. 进行模糊 Hash 和模糊正则匹配
6. 综合各分类值和匹配结果给出最终判定,如图所示。
非平衡数据集评估
在对训练模型的评估过程中,为了接近真实环境的正负样本比,我们收集了 GitHub 上 Star 数量处于各种层次的正常文件样本,也包括一定数量的非 PHP 文件,使得正负样本比例(常规文件:Webshell)达到8000:1。在最后的评估测试中,正样本数量大于 15 万个,使得训练模型更有说服力,确保了牧云可以在生产环境中达到设计的监控检测效果。
产品评估
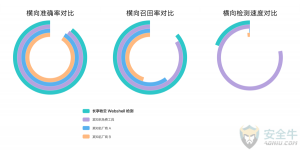
在产品研发最终阶段,我们将牧云产品与友商产品进行了横向对比测试(最外圈为牧云产品),以下图表分别从准确率(1:1 正负样本中正确报出占总报出的比例)、召回率(负样本中报出比例)和检测时间(1:1 正负样本,每万个样本)评估,牧云可以做到在较短时间内以较高的准确率、极高的召回率对大量样本文件进行准确的监控检测,尽可能避免客户的损失。
牧云(CloudWalker)受到业内人士广泛关注,不断有用户询问产品细节与开源进度。
我们也在持续不断打磨,使创新技术在落地的过程中更加贴合用户需求。
牧云最终实力几何,我们和你们一样拭目以待。
更多开源信息请持续关注!
申明:本文系厂商投稿收录,所涉观点不代表安全牛立场!
长亭科技
全球顶尖的网络信息安全公司,专注为企业级用户提供专业的网络信息安全解决方案。 全球首发基于人工智能语义分析的下一代 Web 应用防火墙,颠覆了传统依赖规则防护的工作原理, 为企业用户带来更智能、更简单、更省心的安全产品及服务。

