
5月6日
RSA Conference 2024
将正式启幕
作为“安全圈的奥斯卡”
RSAC 创新沙盒(Innovation Sandbox)
已成为网络安全业界的创新标杆
创新之下
与绿盟君一道
聚焦网络安全新热点
洞悉安全发展新趋势
走进Reality Defender

公司简介
1)公司概况
Reality Defender是2021年成立的一家专注于检测深度伪造(Deepfakes)和合成媒体(Synthetic Media)的初创公司,提供针对多种模态的深度伪造检测服务,其研发的检测工具适用于识别人工智能合成和伪造的文本、图像、视频和音频,为政府机构、金融企业、媒体以及其他大型组织提供深度伪造检测解决方案。Reality Defender的官网[1]提到其曾协助亚洲国家公共广播公司、跨国银行应对深度伪造引起的虚假信息传播和身份诈骗。
目前Reality Defender已获得1500万美元的A轮融资,由风险投资公司DCVC领投,Comcast、Ex/ante、Parameter Ventures和Nat Friedman’s AI Grant等机构参投。
2)产品功能
Reality Defender提供了多种深度伪造检测工具,包括针对人工智能生成的文本、图像、音频和视频的检测工具,能够识别常见的换脸、克隆语音、欺诈文本等深度伪造威胁。这些工具以API或Web应用程序的形式提供,用于分析和寻找待检测样本中的深度伪造修改迹象和线索,从而判断用户上传文件中的数据是否为合成或冒充的。

为了构造更加鲁棒和高精准度的深度伪造检测系统(Deepfake Detection System),Reality Defender集成了一组人工智能检测模型而非单个模型,通过从多个角度对上传文件进行检测,最终输出预测概率和可视化结果。

总而言之,Reality Defender提供的深度伪造检测工具能够识别虚假的媒体内容和有害信息,帮助团队防范和应对人工智能深度伪造威胁。
深度伪造与检测技术
1)深度伪造
2017年Reddit用户“deepfakes”发布了第一个深度伪造算法,该算法能够将知名演员的面部投射到色情视频中;2018年BuzzFeed使用FakeApp软件制作了一段关于奥巴马演讲的深度伪造视频;2019年有攻击者基于人工智能软件成功冒充德国总公司首席执行官的声音,诱导某英国能源公司CEO向攻击者的账户汇入22万欧元……自深度伪造引发关注以来,用于深度伪造的应用程序(如FakeApp、Faceswap等)不断涌现在互联网上,使得任何非技术人员都能够轻易、低成本地制作各类伪造视频,虽然深度伪造在电影制作领域发挥着正面积极的作用,但也引发了公众对社交媒体上虚假新闻传播、身份冒充、电信诈骗等现象的恐慌,严重破坏社会信任与信息秩序。
深度伪造(DeepFake)是使用深度学习算法捕捉人的面部表情、动作、声音特性,并学习如何替换图片或视频中的人脸、如何合成虚假逼真语音的一类攻击。深度伪造内容往往难以通过肉眼辨别。
在图像、视频的视觉伪造任务上,深度伪造技术需要对人脸进行篡改,方式主要分为两种:一是换脸伪造,对人脸进行替换或是合成新的人脸;二是面部修饰,在不修改人脸标志的情况下,对原始人脸进行部分属性的修改,如伪造表情、伪造特定动作。视觉深度伪造技术通常以卷积神经网络(Convolutional neural network, CNN)、生成对抗网络(Generative adversarial networks, GAN)作为基础架构进行风格迁移和人脸缝合,同时结合一些深度学习技术提高生成内容的真实性和稳定性,如Faceswap-GAN[2]中引入Kalman filter、高重构损失以消除换脸导致的抖动、改善眼部区域生成质量。
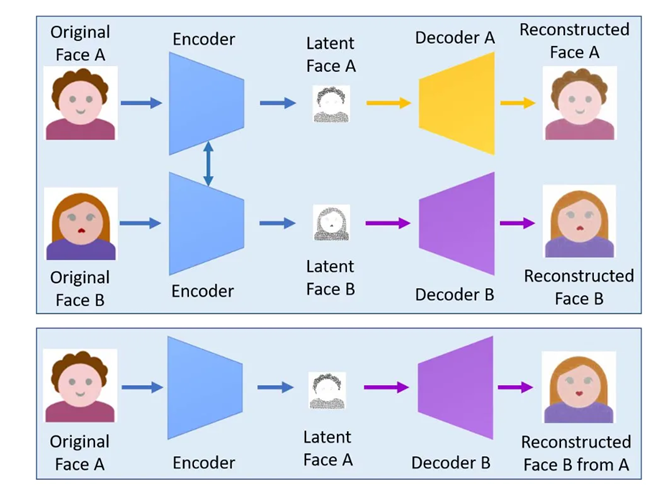
在音频深度伪造任务上,深度伪造技术可以进行文本到语音合成(Text-to-speech synthesis,TTS)和语音转换(Voice conversion),其中文本到语音合成对指定文本生成语音输出,语音转换在保持语音内容不变的情况下实现原音色到目标音色的转换。音频深度伪造技术通常涉及隐马尔可夫模型、高斯混合模型、自编码器、自回归模型和生成对抗网络等人工智能模型,结合频谱转换、膨胀卷积等技巧确保音频样本的高保真度。
近年取得技术突破的生成式大模型也成为了深度伪造的催化剂,生成式大模型能够更精准地模拟人类面部表情、身体动作和音色,使得深度伪造内容更加逼真和难以辨别,导致深度伪造内容的传播更加广泛、难以控制。
2)深度伪造检测
最常见的图像和视频深度伪造检测技术是基于伪造前后图像的特征差异或GAN生成图像的特征的检测方法。前者通常具有较好的泛化性,使用深度学习模型对变化特征进行提取,例如对图像/单一视频帧的伪影进行检测或对视频帧之间的时间特征进行检测;后者则更加有针对性,对于深度伪造方法非常青睐的GAN模型,由于其在合成样本时的颜色处理方式、色度空间统计特征等会与相机拍到的真实图像存在差异,甚至会在生成图像中留下稳定的模型指纹,因此对GAN生成的图像特征进行检测也形成了一个独立的方向。

而对于一维的音频伪造信号,现有的检测方案主要依赖生物信息(如语速、声纹和频谱分布等)的差异化特征检测伪造语音中的特殊噪声信息和伪造痕迹。同时凭借单一的特征难以全面掌握伪造线索,因此一些SOTA方案会融合多种互补特征信息提高检测算法的鲁棒性。
当前虽然深度伪造检测技术的研究已经取得了进展,但随着深度伪造技术的快速推进,现有方案仍有一些亟待解决的问题:
提升检测算法的泛化能力与鲁棒性
现有检测方法缺乏对多种伪造类型共同特征的学习,过于依赖训练数据的分布和特征,在面对训练集以外的伪造类型、未知的伪造数据时检测能力明显下降。且当检测算法被用于现实复杂场景时,检测准确率会受到影响。因此,在提高检测算法训练数据多样性的同时,也应当加强检测算法对多种特征的关注和提取,综合考虑光照变化、面部纹理特征、面部轮廓变化、面部五官位置以及声纹、音素、语速等多角度特征,提高检测算法的泛化能力和鲁棒性。
推进多模态检测算法的研究
多数已有检测方案仅关注了单一的伪造样本类型(图像或语音),属于单模态伪造检测。但为了更为逼真的效果,现实中的深度伪造技术可能会对视频和音频同时进行伪造,因此研究多模态伪造数据检测技术变得迫切,也可以像Reality Defender一样通过集成多种检测算法来提高对实际复杂深度伪造技术的检测精度。
总结
爆发的ChatGPT、Sora等生成式模型成为了深度伪造技术的新武器,深度伪造技术的飞速进步加大了检测难度。除了Reality Defender,很多科技巨头和初创公司都在人工智能深度伪造检测领域投入研究和工具开发工作,如英特尔FakeCatcher、深度假检测初创公司Optic、2014年成立的Blackbird.ai都在致力于识别人工智能篡改生成的数据。可以预见,未来深度伪造检测产品将会更注重和贴合实时检测、多模态检测需求,提高检测可靠性和准确率,国内外也会针对深度伪造出台法规政策、行业标准,应对更加成熟复杂的深度伪造技术,为深度伪造检测产品的发展提供良好的市场环境。
参考文献
[1] http://www.realitydefender.com
[2] Faceswap-GAN. https : / / github . com / shaoanlu /faceswap-GAN.
[3] Nguyen T T, Nguyen Q V H, Nguyen D T, et al. Deep learning for deepfakes creation and detection: A survey[J]. Computer Vision and Image Understanding, 2022, 223: 103525.
[4] David G¨uera and Edward J Delp. Deepfake video detection using recurrent neural networks. In 15th IEEE International Conference on Advanced Video and Signal based Surveillance (AVSS), pages 1–6. IEEE, 2018.


