安全牛于11月24日首次公开发布了《网络安全体系设计方法论》,旨在给企业或机构提供一个最佳实践的参考,以帮助企业真正提升对网络安全工作的认识,并在安全建设和运营中不断成长。

这个方法论只是一个安全总体建设的框架,需要不断的深入、补充和完善。而安全大数据平台在未来几年是企业安全能力建设的核心,也是第一步。《网络安全体系设计方法论》中也提到,数据是安全能力的核心。企业首先就要掌握内外部的安全数据和威胁情报,再通过企业安全人员的能力提升,才能逐步提升整体的安全能力。因此,安全牛首先选择了“安全大数据”这一技术平台的架构进行了梳理和深入,并于今日发布研究成果。
《安全大数据平台架构设计参考》
当前网络与信息安全领域,正在面临多种挑战。一方面,企业和组织安全体系架构日趋复杂,各种类型的安全数据越来越多,随着内控与合规的深入,传统的分析能力明显力不从心,越来越需要分析更多的安全信息、并且要更加快速的做出判定和响应。另一方面,新型威胁的兴起,高级可持续攻击要求有长时间的数据才能分析入侵行为和评估遭受的损失。传统的SIEM很难处理多样化的非结构数据,并且传统的应用/数据库架构局限了系统的性能,其能存储的历史数据时长、存储事件的汇总度、查询分析的速度均受到极大的限制。信息安全也面临大数据带来的挑战。
我们需要更深层次的事件关联处理、分析和展现,而当前分布式计算,存储和通信,内存计算,智能分析等技术已经逐步成熟应用,安全数据分析需要使用这些新技术在事件关联、处理和展现能力上进行提升。
大数据安全分析将包括以下几个应用领域:
- 安全事件管理和安全管理平台;
- APT高级持续威胁检测,结合全包捕获技术;
- 0day恶意代码分析,结合沙箱技术;
- 网络取证分析;
- 大规模用户行为分析,结合机器学习技术;
- 安全情报服务;
- 业务风险安全分析等。
目前,基于Hadoop生态圈的大数据平台已经被业界广泛使用,部署规模从几十台,到几万台,可以存储和分析PB级别数据,从网页日志分析,搜索引擎,视频和语音检索都需要操作大量数据资源。而这些数据全部来由Hadoop平台来运算。Hadoop生态圈也在不断完善,能够同时实现并行计算、高速计算、流式计算等计算框架。
安全牛整合了业内资深大数据专家的意见,向大家推荐一个基于Hadoop的安全大数据平台架构,欢迎业界同仁和企业客户与我们共同探讨。近期还将邀请这方面的专家与大家进行更深入的讲座和交流。
安全大数据平台架构
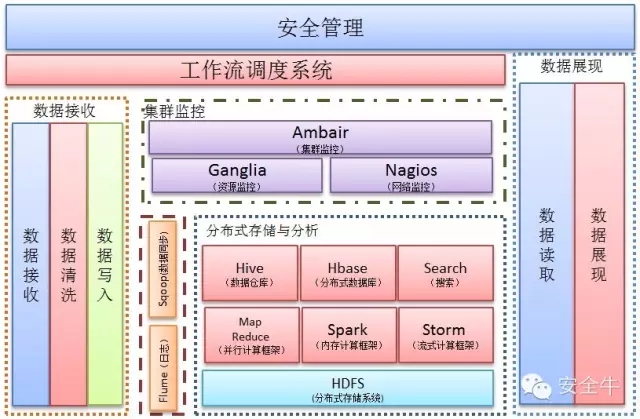
图 1
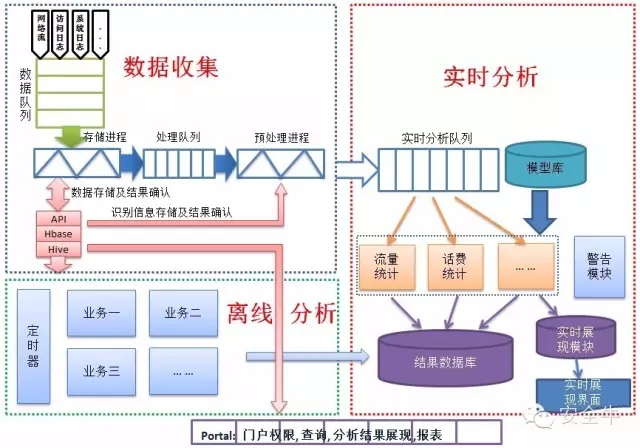
图 2
大数据平台总体概述
此平台集数据采集、数据质量管理、数据存储与分析、集群监控、数据同步、数据展现、数据安全管理等于一身。在保证数据安全的前提下,实现从数据接收到存储维护再到展现的数据管理功能。此平台能够对海量数据(包括结构化数据、半结构化数据、非结构化数据)进行存储、维护挖掘等工作。使用目前最前沿的数据存数、分析、管理技术,以此为基础针对数据分析的实时性,分为在线数据分析和离线数据分析。
在线数据分析:往往要求系统对新数据进行实时分析、实时展现,从而达到不影响用户体验的目的。
离线数据分析:对大多数反馈时间要求不高的应用,比如离线统计分析、机器学习等,应采用离线分析的方式。
具备以下特性:
- 先进的技术架构,基于Hadoop的先进分布式计算及存储框架;
- 先进的多层架构,系统维护简单;
- 纵向、横向扩展能力出众,为未来BI发展提供可能;
- 能做到5分钟之内系统扩容,支撑更多终端。
数据采集
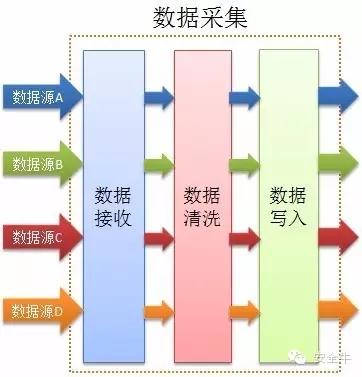
数据采集
数据采集过程中分为三个部分:第一部分收据接收、第二部分数据清洗校验和第三部分数据写入(写入大数据平台)。每个部分全部支持跨平台(多种开发语言)、并行化,能够使数据快速准确的写入到大数据平台中。
数据接收:能够接收来自各种设备的所有类型的数据。
数据清洗:实现并行化数据的校验,简单处理等。
数据写入:校验好的数据通过数据写入程序写入大数据平台。
数据质量管理
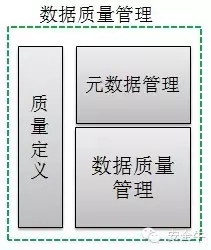
数据质量管理
数据质量管理实现探查接收到的数据发现和评估数据的内容,根据企业的数据质量规则,将对数据进行质量检测。
分布式存储与分析
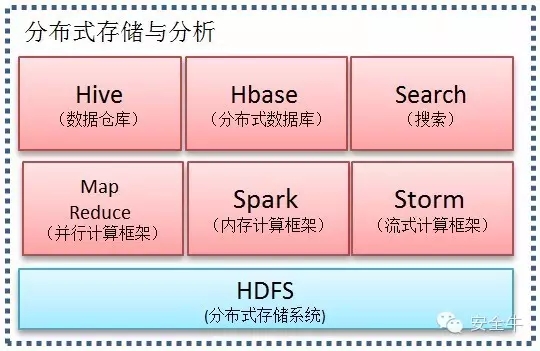
分布式存储与分析
A:大数据平台使用分布式文件系统(HDFS)作为底层存储。特点如下:
1. 支持多数据结构的存储(结构化数据、半结构化数据、非结构化数据);
2. 存储空间无限大;
3. 扩容简易;
4. 自动化数据维护;
5. 支持大文件存储;
6. 容错性强。
B:MapReduce并行计算框架, 对海量数据进行分析计算。特点如下:
1. 移动计算(程序)到数据端,减少网络使用;
2. 能够快速并行的对海量数据进行分析计算;
3. 支持多种开发语言,程序编写简单。
C:Spark内存计算框架,对海量数据进行快快速计算。特点如下:
1. 支持并行计算;
2. 与MapReduce并行计算框架相比内存计算框架整合了内存计算的基元,计算速度更快。
D:Storm流数据处理框架,实现实时性数据处理。特点如下:
1. 简单编程;
2. 多语言支持;
3. 支持水平扩展;
4. 容错性强。
E:Hive数据仓库,存储结构化数据。
依赖于分布式存储和分布式计算框架。主要功能为将HQL(类SQL)转换为并行计算框架能够识别的程序。
F:Hbase分布式数据库,主要以表格的形式存储数据,存储数据依赖于分布式存储。特点如下:
1. 实时相应读取请求;
2. 数据表的行、列可以无限扩展;
3. 数据自动维护。
G:Elastic Search搜索,基于Lucene的搜索服务器。
它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,可达到实时搜索的能力。
集群监控
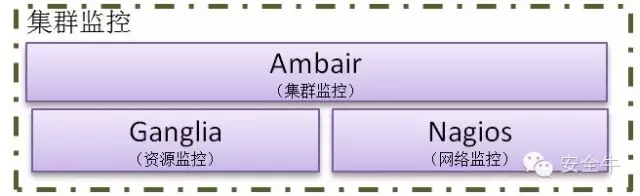
集群监控
集群监控管理由Ambari、Ganglia、Nagios组成。以实现对集群的安装部署、管理监控等功能。
Ganglia 主要对集群的资源进行监控管理。包括CPU 资源、内存资源、网络资源。监控资源使用百分比,高峰期等,并将此信息绘制成直观、易于理解的统计图。
Nagios 对于集群的安全、资源使用值进行监控,在发生问题的情况下向有关的管理人员发送邮件给予提示。
Ambari 提供界面化的方式实现集群安装部署、管理维护、配置文件修改、集群扩容等,同时与Ganglia、Nagios协同工作,实现对整个集群的监控管理。作为大数据平台的核心控制系统,对大数据平台的各个环节进行控制,且对运行过程中的各个组件的关系进行控制,同时对各个环节进行监控,通过监控异常报警来提高系统的稳定性和异常响应速度。
数据展现

数据展现
数据展现,实现将大数据平台存储的部分数据按着业务需求进行展示。
数据读取,可实现根据业务需求对目标数据进行读取,读取后传递给数据展现模块。
数据展现,或得到数据后可根据角色的不同展示不同的数据。
以上数据读取和数据展现过程采用并行跨平台化的处理方式实现。
数据安全
数据安全从最初的数据接入到最终的数据展现的安全问题。
中间包括数据源系统、数据收集、消息系统、实时处理、存储、数据库等各个模块的数据安全以及整条线的安全。
工作流调度
工作流调度系统,主要实现对于数据接入、数据预分析、存储、挖掘的各个环节进行可控的管理调度。
数据收集

数据采集
数据收集,主要实现各种设备的不同类型数据的收集工作。对收集到的数据初步校验后存入大数据平台。部分数据需要进一步预处理,可通过系统API进行再次预处理工作。同时可实现将数据存储至Hbase数据库或者Hive数据仓库内。
离线处理

离线处理
离线处理,主要实现对现有已经存储至大数据平台的数据进行分析计算。用于对实时性要求不高的业务需求。可实现预测性分析、数据挖掘等操作。
实时分析
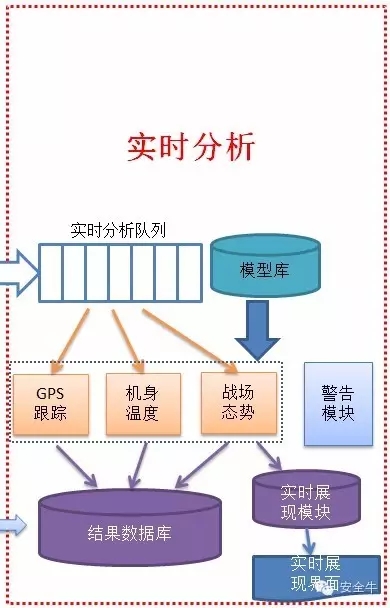
实时分析
实时分析,用于实时显示动态数据信息,可以用于实现数据可视化业务的需求。可对接收到的数据进行实时分析,分析完成后存入结果数据库或者直接显示到可视化界面中。