数据已成为组织中最有价值的信息资产。数据治理的公认最佳实践是分类分级管理,人工智能技术的成熟使海量数据实时分类成为可能。网络安全初创企业思睿嘉得,在机器学习和自然语言处理方面的技术一直受到业界的关注。近日,安全牛与思睿嘉得就此话题进行了深入探讨,这也是其令人惊艳的数据分类引擎效果和背后的先进技术首次见诸媒体。
思睿嘉得致力于将机器学习、自然语言处理、和数据挖掘等先进技术应用于内容识别、数据治理、数据安全、检测与响应、和威胁情报等领域。其自主研发的轻量化人工智能引擎,使用场景优化独有算法和代码实现,适用于多种业务场景,可分布式前置嵌入各种平台,有效扩展了人工智能在信息安全中的应用范围,被众多合作伙伴厂商所青睐并采用,2015年入选“中国网络安全企业50强”评选中的十大安全领域初创企业。
安全牛:能否简明扼要地介绍数据分类分级引擎?
思睿嘉得:从零行代码开始自主研发的内容识别引擎,应用机器学习、自然语言处理、和文本聚类分类技术,能对数据进行基于内容的实时精准分类分级。此无监督机器学习引擎可分析大量未经标注的原始文档集,自动按照内容进行主题梳理,并可通过人工干预灵活调整语义相似度,获得满意的聚类效果。之后,将聚类结果作为标注样本,实施有监督机器学习,提取短句或长组合词作为语义特征,自动生成文本分类规则库,在这一过程中,用户亦可人工干预特征选择,也可使用反向样本加强训练。将文本分类规则推送至部署在组织中端点、服务器、和网络等处的轻量化分布式分类器,即可实时感知关键数据的分布和使用状况,为数据治理提供基础支撑。
安全牛:太多专业名词了,我理解就是可以自动梳理杂乱无章的多篇文档到不同主题?
思睿嘉得:是的。我们今天会使用单机版软件进行演示,与服务器版引擎实现的效果相同。在这个演示当中,我们选择一个包含大量文档的文件夹目录输入软件,开始自动分析。软件能够解析不同格式文档中的文本内容,智能提取语义特征,并按照内容相似度进行聚类。如下面的截图所示,把文档划分到液化气/燃料油/汽柴油市场、国际石油市场、以及IT运维等分类。此过程中并无人工干预,样本也未经人工标注,是无监督机器学习的典型场景。
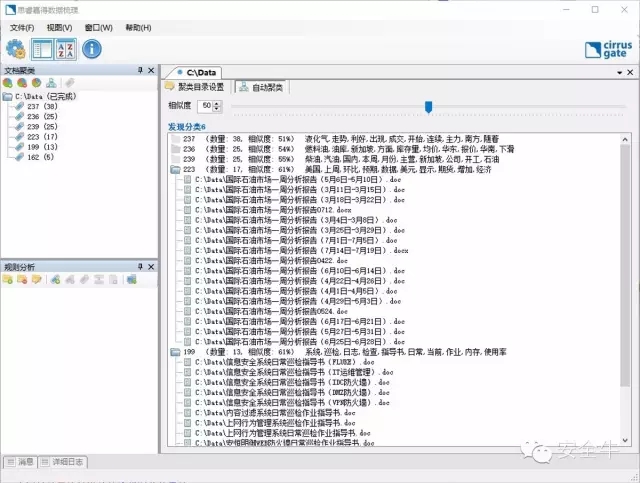
安全牛:每一类后面的词是什么意思?关键词吗?
思睿嘉得:为了帮助用户快速了解无监督聚类的结果,我们在这里加入简单文本摘要算法,将具有代表性的关键词罗列出来,用户能一目了然知道每个分类大概是什么主题内容。需要说明的是,这些关键词并不是分类器会使用的语义特征,后面讲到有监督训练时会看到软件能选取更有意义的短句或组合词。
安全牛:不用人工干预确实让我眼前一亮。但如果自动聚类结果与用户预期有偏差,那需要如何调整呢?
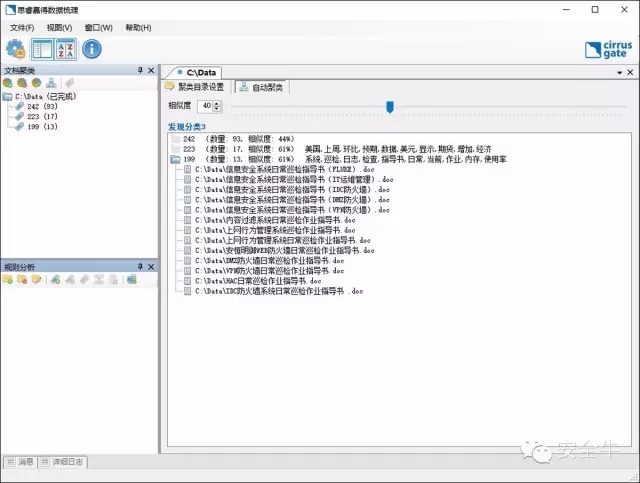
思睿嘉得:可以看到在聚类结果上方有内容相似度调整的控件,我们拖动指针可以立刻观察到不同的聚类结果。例如下图所示,将相似度调到40%,石油市场报告从四类变成了两类:国内石油市场、和国际石油市场,IT运维文档还是单独的一类。
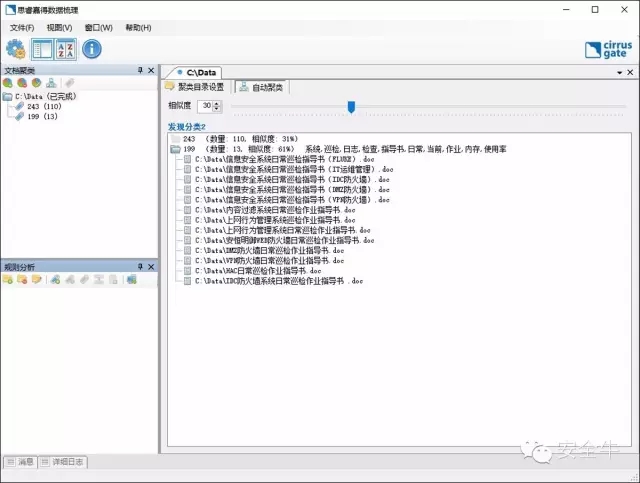
再降低相似度到30%,所有石油市场报告变成了一类,而IT运维文档仍是一类。
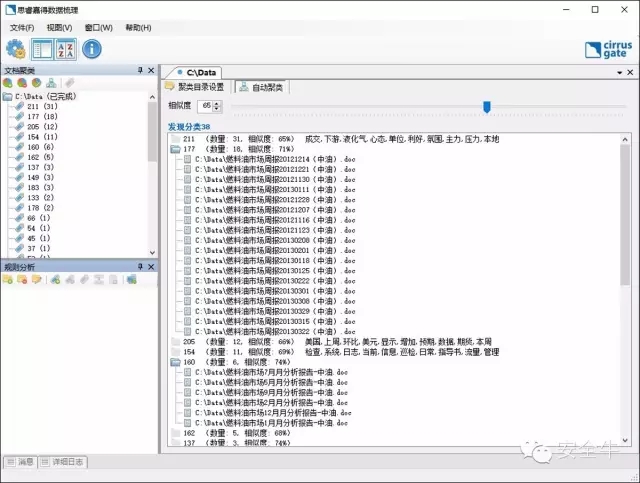
如果反方向拖动指针,将相似度调高到65%,可以观察到原来被分为一类的燃料油市场报告,被进一步细分为周报和月报。
便捷的人机交互界面,背后隐藏着经过大量精心调优的自然语言处理、机器学习、和数据挖掘多种算法。用户梳理数据时,根据不同的管理目标和要求,可以灵活通过手动干预调整相似度,将文档聚类成满足其需要的主题划分。
安全牛:汽柴油和燃料油市场分析报告虽然细分领域很接近,但可以被人工智能划分成两类,这听起来还比较容易理解。但为什么同样是燃料油市场报告,还可以被区分成周报和月报两类呢?
思睿嘉得:虽然同为燃料油市场,但是周报和月报的用途和内容侧重点不同,用户撰写时的关注角度和着眼点也会不同,带来的是内容结构和描述用词都存在一定差异。这些细节上的异同通过人工智能引擎很容易区分开,因此能达到细分领域精准分类的效果。
安全牛:随后就可以使用聚类结果自动训练机器?
思睿嘉得:是的,接下来是有监督机器学习,进行语义特征的提炼和选取,为自动生成分类规则做准备。我们新建一个分类,命名为汽柴油市场分析,将聚类结果中对应的一组样本导入,搜索语义特征的结果如下图所示。
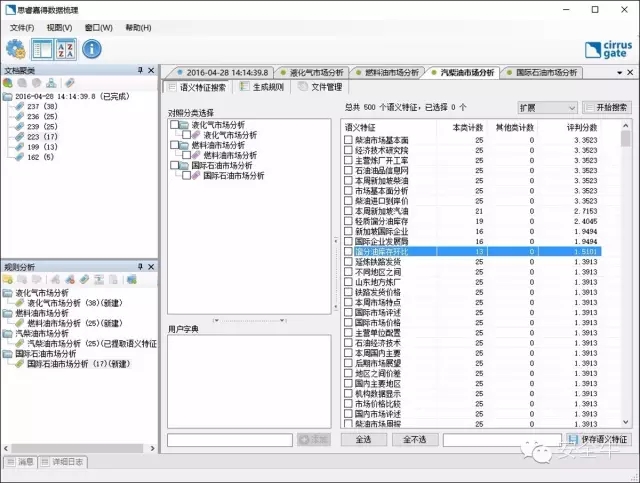
在市场上热炒的中文分词先进技术,在我们的引擎里只是最基础的一个功能步骤。切词算法也有明显的高下之分。大家可以看到,在这个页面中,诸如“馏分油库存环比”这样专业的词汇也被正确提取。我们的自然语言处理引擎无需依赖专业词库。新词和专有名词发现能力只是第一步。一篇一万字的文章能切出近一万个候选语义特征,但是这里面哪个特征更重要,对文本分类更有意义,需要更多更高级的算法去评分筛选。我们的软件会对语义特征进行智能排序并向用户推荐。
安全牛:语义特征是什么?为什么不是关键字?
思睿嘉得:很多用户会关心此问题。高质量的语义特征一般指短句或长组合词。例如,上个页面中显示软件提取的“柴油市场基本面”,如果使用不够优秀的中文分词和特征提取算法,就会得到 “柴油”“、市场”、“基本”、和“面”四个关键词;显然,我们软件所选取的组合词更能代表主题内容含义,在进行数据分类时更准确且效率更高。相比之下,用关键字和正则表达式技术在文本分类中的内容识别效果很差。举个大家都理解的实例,当谈到识别合同分类时,用户第一反应是“合同”关键字,但很多不是合同的文档里仍会含有“合同”两字,而有些合同里根本就没出现这个关键字,而是通篇使用“协议”或“谅解备忘录”等。即使通过撰写正则表达式表示多个关键字组合逻辑,仍会出现大量误报或漏报。而人工智能引擎通过计算高达数百个语义特征,在多维向量空间中构造出特定分类的数学模型,因而具有极高的识别准确率。即使替换或删除一些关键词,依然能准确进行文本分类。
安全牛:语义特征评分和排序是如何算出来的?按照词出现的频次多少吗?
思睿嘉得:语义特征的评分,并不是简单按照出现次数去统计计算的,而是根据该短句或组合词在本类样本中的语义重要程度,综合多种维度因素进行排序。例如,“馏分油库存环比”在本类计数中只出现13次,而“国际市场评述”和“后期市场展望”分别出现了25次,但是系统算法认为“馏分油库存环比”更具备此类样本内容的典型代表性,所以反而评分更高且排列靠前。这才是真正人工智能引擎实现自然语言理解后的效果。
安全牛:那下一步如何自动生成数据分类识别规则呢?
思睿嘉得:在语义特征列表中选择恰当的组合并保存,简单点几次鼠标便可输出分类识别规则至一个独立文件。将此规则文件导入至服务器,下发至分布式轻量化分类引擎,即可在海量的数据中快速、准确的识别并找出所需要找到的数据。
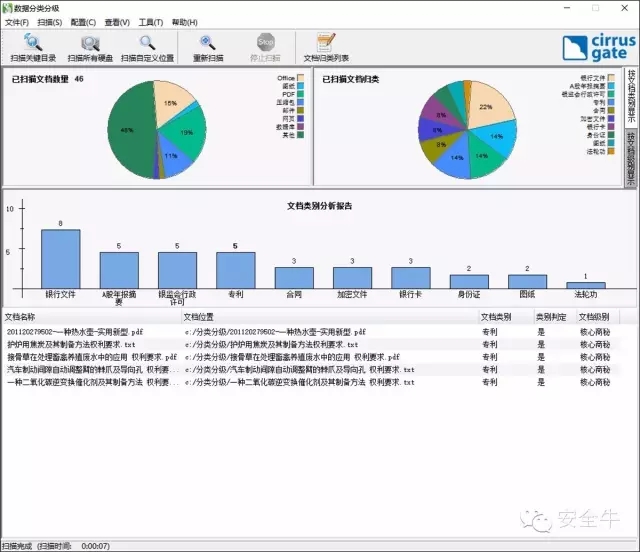
安全牛:你们软件的易用性确实让我印象深刻,但我看到各种技术报道说人工智能不是有很多复杂算法吗?参数调优不是很麻烦吗?
思睿嘉得:是的,机器学习、自然语言处理、数据挖掘都有很多复杂算法,特定算法在特定领域更有效果,也有不少研究者靠参数调优就发表了很多论文。我们早期版本的用户界面上曾有十几个参数tab页面,每个页面都会包含特定算法的多个参数可供调整优化。但是,在后来的实际应用过程中,我们发现这种操作对于用户来说过于复杂,因为能理解参数调优原理的用户凤毛麟角。因此,我们做了大量的产品化工作,目前只在界面上保留了内容相似度调整和语义特征选取两个人供干预的选项,大幅减少了用户干预场景,极大幅度提高了易用性。更突出的优势是,我们成功地克服了跨行业算法标准化的难题,无论金融、电信、能源、政府、制造等任何行业用户,都可以直接使用标准版本,无需定制仍可获得满意效果。
安全牛:人工智能数据分类引擎有哪些应用场景?
思睿嘉得:数据治理已成为信息安全的重要关注点,数据分类引擎已成功应用在邮件内容过滤、保密文件管理、知识挖掘、情报分析、反欺诈、电子发现和归档、数据防泄漏等领域。此引擎使用经过优化的独有算法和代码实现,稳定、高速、低能耗,计算能力要求低,适用于多种业务场景,可分布式前置嵌入各种产品和平台,已被众多合作伙伴厂商所青睐并采用,在各行业多家财富500强公司中创造着巨大价值。


