问题足够严重可以停止云服务 微软发布云安全问题归责
微软近期发布了Azure安全指南,明晰问题归责细节。共有两份文档阐述了问题的解决方法。其一为《云计算共有责任》,解释微软的安全责任分类方式。
基本原则是:
1. 内部IT的所有问题都是客户的责任
2. 将Azure作为基础设施即服务(IaaS)使用时:
- 建筑、服务器、网络硬件和管理程序是微软的责任
- 操作系统、网络配置、应用程序、ID、客户端和数据是客户的责任
3. 作为平台即服务(PaaS)使用时:
- 网络控制是微软的责任
- 操作系统、应用程序、ID、客户端和数据还是客户的责任
4. 使用软件即服务(SaaS)时,全都是微软的责任,但数据分类、终端安全和用户管理还是你的责任
另一份文档是新的白皮书,题为《微软Azure云端安全响应》,阐述了该公司在Azure出现问题时会怎样响应。
白皮书显示,微软采用以下5个步骤维护Azure边界安全:
- 客户通过客户支持门户描述归结到Azure基础设施的可疑活动(非客户责任范围内的活动);
- 安全漏洞通过secure@microsoft.com被报告到微软安全响应中心(MSRC)。MSRC与合作伙伴和全世界的安全研究人员合作,防止安全事件发生,提高微软产品安全;
- 安全红蓝对抗。红队由技术专家组成,攻击Azure的潜在漏洞;蓝队是安全响应团队,需要发现红队的攻击活动。红队和蓝队的行动都被看做是验证Azure安全响应工作在管理安全事件的方式。红蓝对抗活动是出于确保客户数据防护的责任需求而进行的;
- Azure服务内部监视和诊断系统对可疑活动做出检测。警报的发出可能是以基于特征码的方式,比如反恶意软件、入侵检测,又或者是通过分析语气行为的算法来报警异常;
- Azure服务操作员升级。微软员工接受培训,掌握发现和升级潜在安全问题的能力。
文档的剩余部分没什么大用,不过,关于事件缓和动作的章节倒是表明微软的Azure修复动作可能会导致“短时宕机”。
“此类决定不会轻易做出。一旦这种激进的缓解措施实施,通知客户宕机和修复时间线的标准流程将启用。”
其余微软响应过程如下,以图表形式呈现。
微软云事件响应模型
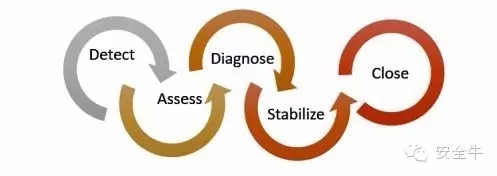
事件响应活动和状态
检测->评估->诊断->稳定->善后

事件响应阶段
阶段 描述
1. 检测:标示了一场事件调查的开始
2. 评估:事件响应团队值班人员评估事件影响和严重性。基于证据,该评估可确定是否招来安全响应团队做进一步行动。
3. 诊断:安全响应专家进行技术性调查或取证,制定控制、缓解和应变策略。如果安全团队认为客户数据有可能落入未经授权人士之手,客户事件通告过程将同步进行。
4. 稳定,修复:事件响应团队制定修复计划。诸如隔离受影响系统之类的危机控制步骤将随诊断过程立即展开。更长期的影响缓和可能会在眼前危机渡过后着手。
5. 善后:事件响应团队勾勒出事件完整视图,借以修订安全策略、规程和过程,防止类似事件再次发生。
一环扣一环:微软安全自旋。
关键词:


