CrowdStrike、Cylance、Endgame等安全厂商将 Hello World 标为不安全或恶意。

上周,8月10号,昵称“zerosum0x0”的安全研究员在推特上贴出了一张有意思的图片,那是某程序调试版本的代码。
该代码就是每个新手程序员入门必练的“Hello World”样例程序。该程序提交到VirusTotal时,多家安全公司都将它当成了问题来标记。
安全媒体 Salted Hash 想知道为什么训练代码被认为是恶意的,于是邀请了各大厂商阐述个中缘由。
围绕机器学习和人工智能的议论,在安全世界已经喧嚣了一年有余。利用这些技术的厂商竭尽所能地捞钱,并不断提升性能以成为市场上无可争议的王者。
zerosum0x0的实验之所以会引发关注,是因为标记该端代码为恶意的厂商都是标榜采用机器学习的先进防御系统。
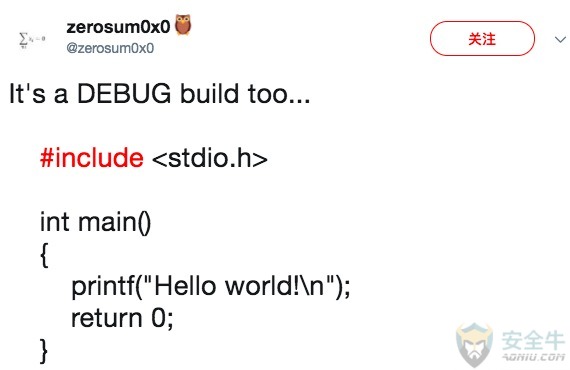

问题代码如上图所示。再强调一遍,这是训练代码,所有新手程序员都用的。那么,为什么就这么一个基础代码,会被Cylance、Sophos、迈克菲、SentinelOne、CrowdStrike和Endgame这样的著名厂商标记为可疑/有害/恶意呢?
zerosum0x0的样本只是其中一个测试,有7家厂商做了标记。其他测试中,昵称“_hugsy_”的用户去掉了一句“printf”屏幕输出语句,依然被标记。只不过,_hugsy_的删除动作反而诱使另11家厂商报告该“Hello World”不安全、恶意或是木马。其他人做了同样的测试,结果雷同。
zerosum0x0证实,他们也用非调试版本进行了测试,虽然是漫不经心的。“理论上,机器学习可以从调试版本推断出更多信息。”
那么,为什么这些高端产品,来自著名安全厂商的高端产品,会将如此基础又无害的代码标记为恶意呢?
事实证明,对某些人来说,事情理应如此;而对另一些人来说,不过是因为VirusTotal没有使用全套产品而已。看起来默认是标记为可疑的。
在进入厂商解释环节之前,必须指出,VirusTotal一直坚持自己不是用来进行安全产品对比分析的正确工具。虽然这不是本文焦点所在,但我们对贴出的结果还是很感兴趣的。
Salted Hash 联系到的标记了“Hello World”的厂商包括:Cylance、Sophos、迈克菲、SentinelOne、CrowdStrike、Cyren,及它们的消费级产品F-Prot、Endgame、F-Secure和Bitdefender。
Salted Hash 询问了为什么“Hello World”会被标记,以及这些厂商都是怎么保持低误报率的。除3家厂商以外,其他厂商都在截止前给出了解释。
迈克菲、F-Secure和CrowdStrike并未就初始评论请求做出回应。当这一事实被公开提及的时候,F-Secure和迈克菲直接联系了 Salted Hash,但在本文撰稿时依然没有提供任何评论。而当文章发布后,CrowdStrike、F-Secure和迈克菲都回复了。
以下就是相关厂商做出的回应:
1. Cylance

Cylance引擎并非杀毒软件(AV)引擎。与AV不同,Cylance不倾向于让所有东西都运行起来。我们的技术不会在评估之前假定某文件是良性的。我们的方法是单独估测判定每一个文件,只要不符合我们定义为良性的模型,就倾向于不良文件。
在缺乏决策所需的大量数据,缺乏任何真正可以判定为良性的模式的情况下,引擎十分依赖看起来很奇怪的结构性比特,并就此做出倾向于不良文件的判定。
训练模型的时候,我们都是基于亿万良性和不良样本,每个文件都会比对数百万潜在数据点……
基本上,只要进行倾向于不良的动作,代码就会被判定为“不良”。但也会因为没有做偏向于良性的动作,而被判定为不良。所以,在所提供的最基础的样本中:如此之小的样本没有表现出任何不良倾向,但也没有展现出任何良性动作;单函数程序往往都是恶意软件;调试版本总是很奇怪的;用mingw而不是 Visual Studio 编译的东西往往很古怪。于是,输出的二进制文件也就“异常”了。
2. Endgame

在推特上热炒这些“Hello World”样本之前,我们自己的内部研究就表明,我们的模型和其他模型易受这些玩具样本的影响。
Endgame的机器学习恶意软件检测,在客户执行文件之前,采用静态特征来确定给定文件是恶意还是良性的。机器学习模型是上千万训练样本软件的不完美总结。
作为一个不完美的模型,显然是会出错的,但依然在检测前所未见的恶意软件上极端有用,远比依靠已知恶意软件家族特征的方法有用。
对我们的模型和其他基于静态特征的机器学习模型来说,此案例中模型有可能出错,因为在训练数据集中,模型看到的是:
很多真实恶意软件样本都是很小的未签名二进制文件;很多真实恶意软件样本的入口点(.text)段都很小,比如解压模块的释放器;很多真实恶意软件样本试图通过某种方法对静态分析隐藏其导入部分,所以其导入表都非常小。
与之相反,几乎没有什么“有用的”良性文件会那么小,其罕见程度足以支持上述经验。
值得指出的是,机器学习实际上在预防和检测恶意软件上表现出色,无论是新样本还是知名样本方面都如此。Endgame就是VirusTotal上标记出NotPetya的少数几个。也就是说,所有机器学习模型都有盲点,也会误报。实际上,我们在公布的研究中已经阐明,对某些机器学习模型来说,此类漏洞很容易被利用……
Endgame采用符合大量常见攻击动作的分层防护策略。我们的MalwareScore引擎(在VirusTotal上单独发布)仅是该分层防护策略的一小部分。多层次防护齐心协力向客户报告潜在威胁,给出潜在威胁的完整视图。
幸运的是,推特上的样本是很有趣的极端情况,距离我们的客户群非常遥远。尽管如此,我们仍持续进行更多研究以提升检测率,降低误报率。这涉及到收集数据以增加模型对良性和恶意软件的理解,以及做大量实验以最大化模型性能。我们非常注重解决客户提出的已知误报。所有这些工作,让我们得以向我们的客户和VirusTotal经常发布模型。而且,我们持续与第三方合作,在真实文件上验证我们的模型表现。
3. CrowdStrike

需要理解两个重要方面。首先,CrowdStrike所用静态文件分析机器学习模型对恶意软件检测进行了优化,尤其是绕过特征码方法的那些新型恶意软件家族,同时还避免干扰合法业务应用。然而,偶尔也会发现一些没落入这两个类型的不寻常人工构造文件。
因此,我们显露出信任值,并允许客户设置自己的阈值。在这个案例中,我们的文件分析引擎略为激进,一般来说,这种行为是有意的:如果某文件看起来不像合法有用应用程序,同时又表现出不寻常的特征,那么明智的决定就是阻止其执行。避免看起来奇怪但有可能良性的物品,应该是你非常熟悉的一个概念,如果你以前打开过办公室冰箱的话。
其次,仅仅静态文件分析(大多数厂商在VirusTotal上提供的就只有静态文件分析),不足以保证安全。很容易创建表现良性但被特征码和ML引擎检测的文件,同样地,绕过检测的恶意软件也是可以创建的。这对基于特征码的引擎来说非常有可能,但只要多花点时间精力,同时绕过基于机器学习的静态文件分析也可以。因而,CrowdStrike Falcon 仅将静态文件分析作为威胁检测的多种技术之一,将其融合到其他多层防御当中,比如高级攻击指标。
4. SentinelOne

SentinelOne采用在完整SentinelOne终端防护平台(EPP)上协同工作的多个引擎,包括一个静态机器学习引擎(VirusTotal上那个)和一个动态ML引擎(代理商才可用)。
每个引擎都用ML技术将文件和事件分类为威胁(高置信度检测)或可疑(低置信度检测),而组合起来又一起享受完整的系统上下文。VT不支持信任评分,所以,即便低置信度检测(又名“可疑”),在他们的反馈中也被标记为威胁/恶意软件。
本案例中,经受测试的二进制文件被检测为可疑,可能是因为以调试模式编译的原因。同样的代码若以发布模式编译,我们就不会检测为可疑了。这在生产环境中通常不成问题,因为客户会在缓解前审查可疑项目。
我们严肃对待误报和漏报问题,从不同角度解决:
1) 让客户易于将可疑文件编入白名单;
2) 我们有一支威胁研究员团队随时准备好帮助狩猎并分类可疑文件和威胁;
3) 我们每个月都发布新的机器学习引擎。我们每个版本都在改进误报和漏报检测。
5. F-Secure

这种事每隔几年就冒次泡。AV行业用“下一代”ML样本分类系统已超10年。大多数新厂商已经没什么东西是“下一代”了。
我们使用的ML系统,基于我们从样本中抽取的特征来分析样本,且大多数特征是静态收集的,有些是通过在模拟器中执行样本并观察代码运行情况收集的。这些特征来自数百万被归类为恶意软件的样本和数千万乃至上亿干净文件。
最终,你得到的是一个可高度正确地分类恶意和感觉文件的系统。已知恶意软件类型和样本的新实例就会被归类为恶意软件。而干净文件不太会被误分类。
这些分析结果随后被打包进AV特征码数据库,依公司和产品策略要么存于云端,要么发布给所有终端用户;而且取决于公司和引擎,要么包含实际特征码,要么是经过训练的ML数据库。很多时候,除了ML产生的检测,特征码数据库还会含有人为创建的检测,这些往往都更为通用而强大——虽然经常被VT忽略掉或者VT不可用。
但是,一旦某样本不具备任何可被归类的特征,这些系统就容易将之归类成恶意,原因是干净文件极少不干任何事,也极少不含有其他干净文件中的常见特征。这就是“Hello World”问题时不时就跳出来扰人视线的原因。
这常被看做是对安全的逾越,因为被热议的样本不太可能有任何意义,而且很可能包含一些我们尚未抽取出特征的恶意东西。
特别是这个文件可能不会在真实客户中触发虚假警报——因为我们的产品具备误报缓解机制,会纳入除文件分析系统结果之外的其他因素做考虑,因而VT上显示为误报的东西,不会对实际用户触发。
而且,即便对某些用户触发了误报,触发通知也会发送到我们的云端,只要我们有指示误报的元数据,就会自动深入分析样本。这就意味着,触动实际终端用户的切实误报,比VT上看到的少得多,而且通常都很短命。
至于VT上的特定样本。这个案例中,误报是由某个许可组件引发的,该组件的提供商在我们的系统拿到文件进行分析之前,就已经识别并修复了该误报。而且很明显,我们的客户中没有人就该文件进行过查询,所以我也不能说我们能在客户咨询前自动缓解该误报。
6. Bitdefender

Bitdefender采用多层检测,包括用以标记未知文件的坚实信誉系统。即便对用户无害,此类文件也可能含有新鲜编译的应用程序。信誉系统对任何从未见过的文件都保持怀疑态度,但完整Bitdefender产品中的其他技术层通常会进一步分析文件,即便最初在第1阶段被禁也允许其执行。
但是,因为VirusTotal只聚合了一些扫描技术,不像常规的Bitdefender安全套装,有些结果就可能是不准确或不确定的。这也是为什么 VirusTotal FAQ 强烈反对基于其结果进行安全解决方案比对的原因所在。
至于误报问题,用户,或者说测试员,在现实生活场景中是看不到此类检测的,因为我们糅合了多种技术来对文件进行准确分类。
7. 迈克菲实验室

文章中的样本看起来都与迈克菲网关扫描器启发式引擎有关,该引擎就是为检测通过企业网关系统的恶意和可疑文件而设计的。在深度解决方案防御中,该引擎不属于企业终端或消费级解决方案的一部分,这些解决方案的检测资料与网关启发式引擎不同。
该启发式引擎在网关或云端的完整实现,包含其他信任/信誉技术,能够过滤出已知干净文件,以避免错误或提高性能。本案例中,被测试的样本是非常简单的程序,既没有代码签名也没有其他信任指示符,因而启发类引擎在这种上下文环境下很可能就标记了。
8. Cyren(也称F-Prot)

注意:Cyren承认最初封禁了该 Hello World 代码。
8月10日,就在问题出现的同一天,他们被告知了该可能的错误分类。一名分析师看过后,该评级/分类当天就被改掉了。
我们受复杂机器学习驱动的大型自动检测网络,确实偶尔会将良性的对象评级为可疑。我们致力于最小化误报并在发现后尽快修正——这对我们而言与正确封禁威胁同等重要。
9. Sophos

SophosLabs用高级机器学习技术和专家研究员来归类可疑文件样本。当文件被不正确分类时,我们的数据科学团队会快速修正,并重新校准算法。我们的研究人员目前正在调查你们指出的那些可执行文件。
相关阅读
VirusTotal政策变化,点燃反恶意软件产业内战
终端安全战争:VirusTotal新规实际上是和平书?